1.4版本新增加了LinkedHashMap和LinkedHashSet两个新类,同时重构了之前Collection的一些代码,优化和封装了一下。
LinkedHashMap
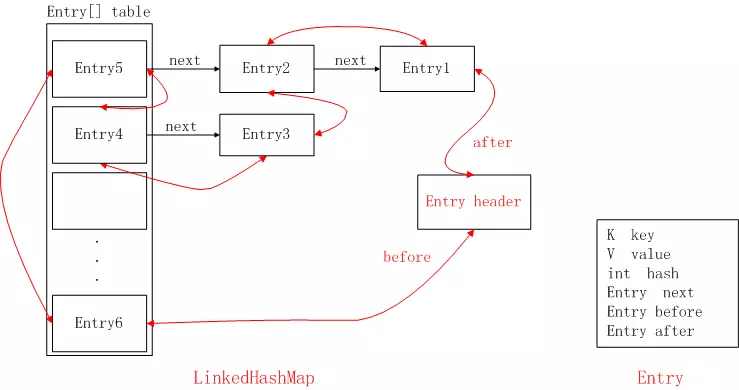
有序的HashMap,继承自HashMap,使用双向链表来保存Entry链表节点。新插入节点时,如果节点重复已存在,会返回直接返回true并不会更新旧的节点???。数据结构跟HashMap一样,只是Entry节点多了一个previous指针,指向上一个节点???。重载了父类HashMap.Entry内部类。
使用链表保存每个节点插入的顺序
???跟TreeMap的性能对比和应用场景??? TreeMap插入的时候就进行排序(存储有序),所有数据存储是有序的,遍历直接输出有序元素。 LinkedHashMap插入的时候不进行排序(遍历有序),所有数据存储跟HashMap一致,遍历的时候才进行排序。
LinkedHashMap.Entry
数据结构:一个Entry[]数组,一个头节点双向链表。
重写了HashMap.Entry节点,实现成了双线链表节点;
private transient Entry header;
// HashMap.Entry 实现 是一个单向链表
static class Entry implements Map.Entry {
final Object key;
Object value;
final int hash;
Entry next;
/**
* Create new entry.
*/
Entry(int h, Object k, Object v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
}
// LinkedHashMap.Entry 实现 实现成了双向链表
private static class Entry extends HashMap.Entry {
// 用来标识节点的顺序的,迭代器通过节点的before、after来有序查找元素
Entry before, after;
// LinkedHashMap.Entry的构造函数没有提供before节点引用?
Entry(int hash, Object key, Object value, HashMap.Entry next) {
super(hash, key, value, next); // 调用父类HashMap.Entry构造函数
}
}LinkedHashMap.Entry继承了HashMap.Entry,所以LinkedHashMap的Entry结构大体如下
// LinkedHashMap的Entry结构定义模型大致如下
Entry {
final Object key,
Object value,
final int hash,
Entry next, // 以上从父类继承,Entry数组节点
Entry before, after; // 新增链表
};构造函数
LinkedHashMap直接调用父类的构造函数,HashMap构造函数在1.4版本中新增了一个空的init方法,该方法由子类实现。HashMap在构造函数里最终会调用init方法。
LinkedHashMap重载了HashMap的init方法,在init方法里实例化了Entry节点header。
private transient Entry header;
private final boolean accessOrder; // true-访问节点排序access-order;false-插入节点时排序insertion-order ??? 默认是false
public LinkedHashMap() {
super(); // 调用父类的构造函数实现,初始化Entry数组
accessOrder = false; // 基于插入排序,即按照节点put的顺序访问
}
// 该方法由父类构造函数调用
void init() {
// 创建一个header节点
header = new Entry(-1, null, null, null);
header.before = header.after = header;
}accessOrder
LinkedHashMap提供两种数据存储排序方式:插入顺序(flase 默认)和访问顺序(true)。
- 插入顺序,指的是,节点按照put时的顺序进行排序,遍历时根据put时的顺序输出节点内容
- 访问顺序,指的是,按get的顺序排序,如果节点被get方法访问,则将该节点添加到链表末尾
访问顺序的应用场景,最终会输出一个按照从近期最少访问到最多访问次数的顺序。
put
LinkedHashMap.addEntry
JDK1.4 HashMap对put操作进行了代码重构,将新增节点操作封装到了addEntry方法,子类LinkedHashMap重写了addEntry方法,实现了自定义的新增节点操作。
- HashMap在JDK 1.4版本中对代码做了大部分抽取封装,方便子类重写父类的实现。
- HashMap的addEntry方法、HashMap.Entry的recordAccess和recordRemoval方法都提供了类似模板策略,具体实现由子类实现。
LinkedHashMap的addEntry方法流程
- 创建一个Entry节点
- 将新节点添加到链表末尾
- 判断是否需要扩容
// 重写了父类HashMap的addEntry方法
// HashMap.put方法最终会调用addEntry实现节点新增
void addEntry(int hash, Object key, Object value, int bucketIndex) {
// 创建节点
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
Entry eldest = header.after;
// 这个方法有意思了,是否需要将最老的元素删除,一般是针对链表容量不够,需要自动删除最老节点策略
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
// 扩容
resize(2 * table.length);
}
}
// 重写了父类HashMap的createEntry方法
void createEntry(int hash, Object key, Object value, int bucketIndex) {
Entry e = new Entry(hash, key, value, table[bucketIndex]);
table[bucketIndex] = e;
// addBefore方法将当前节点插入到链表末尾
e.addBefore(header); // 这里是重要区别
size++;
}
// 默认不需要删除最老的节点,子类可以重写该方法,根据策略删除不需要的节点
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}LinkedHashMap.Entry.addBefore
private static class Entry extends HashMap.Entry {
// 用来标识节点的顺序的,迭代器通过节点的before、after来有序查找元素
Entry before, after;
Entry(int hash, Object key, Object value, HashMap.Entry next) {
super(hash, key, value, next);
}
// 将当前元素before/after表示顺序的指针指向指定的元素(即Header头节点)。
private void addBefore(Entry existingEntry) {
after = existingEntry; // 当前元素的after指向header节点
before = existingEntry.before; // 当前元素的before指向header节点before指针指向的对象,即倒序第二个添加的元素
before.after = this; // 将上一个元素的after指针指向当前元素
after.before = this; // 将header节点的before指针指向当前元素
// 通过这四个步骤,完成每次插入新节点能够记录下插入的顺序。
}
}get
LinkedHashMap重写了HashMap的get方法
- 通过HashMap方法获取到Entry
- 根据访问策略更新Entry顺序
public Object get(Object key) {
// 调用父类的get方法,对应Entry节点
Entry e = (Entry)getEntry(key);
if (e == null)
return null;
// 根据访问策略更新节点顺序
e.recordAccess(this);
return e.value;
}LinkedHashMap.Entry.recordAcess方法
如果accessOrder为true,访问有序,则将get的Entry节点移动到链表末尾
注意,这里的移动只是改变链表指针的顺序,并不会去改变Entry数组的位置。
void recordAccess(HashMap m) {
LinkedHashMap lm = (LinkedHashMap)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}remove
LinkedHashMap直接使用父类HashMap的remove方法实现节点删除操作,并重写HashMap.Entry.recordRemoval方法。节点从集合中删除时,同时从链表也删除。
rehash
// 扩容到新的Entry数组
void transfer(HashMap.Entry[] newTable) {
int newCapacity = newTable.length;
for (Entry e = header.after; e != header; e = e.after) { // 跟1.2一样倒序遍历Entry数组
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}迭代器
HashMap的迭代器也进行了重构。JDK1.2的迭代器为HashIterator,支持3种类型的迭代器(KYES/VALUES/ENTRIES)。JDK1.4将迭代器拆分成3个类(KeyIterator/ValueIterator/EntryIterator),不同类型的迭代器直接实例化对应对象。
LinkedHashMap重写了这三个迭代器,并自定义了自己的迭代器LinkedHashIterator。
LinkedHashIterator
LinkedHashMap重写了HashMap的迭代器实现。还是一样,看它是如何实现hasNext/next/remove三个方法的。
LinkedHashIterator.hashNext()
LinkedHashIterator.nextEntry()
LinkedHashIterator.remove()
// 还重新实现了迭代器 LinkedHashIterator
private abstract class LinkedHashIterator implements Iterator {
Entry nextEntry = header.after;
Entry lastReturned = null;
int expectedModCount = modCount;
public boolean hasNext() {
return nextEntry != header;
}
Entry nextEntry() {
if (modCount != expectedModCount) // 迭代过程中不能修改集合
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry e = lastReturned = nextEntry; // lastReturned 保存当前节点,用于remove方法删除当前几点
nextEntry = e.after; // 获取下一个节点
return e;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key); // 删除当前节点
lastReturned = null;
expectedModCount = modCount;
}
}LinkedHashSet
跟HashSet一样,内部是通过引用LinkedHashMap来实现的
// HashSet 新增了一个构造函数,内部直接创建LinkedHashMap来实现。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}NIO
Buffer,Channel,Selector。
这里是一个重点