1.5版本新增加,集合框架新增了Concurrent并发包和Queue队列结构以及Atomic原子类型。
Queue
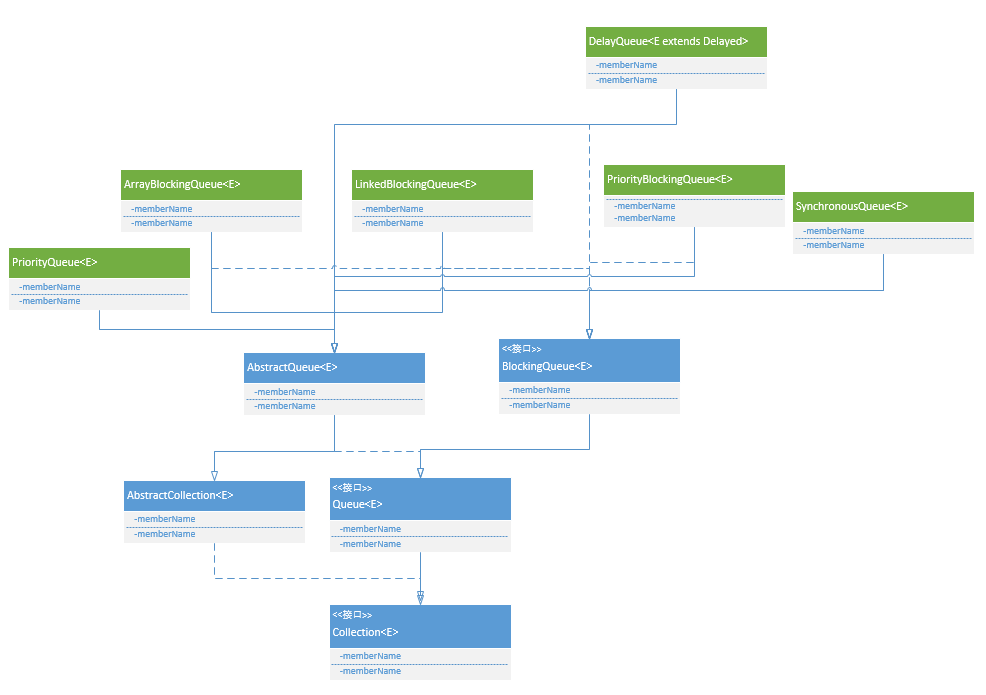
Queue接口定义了队列的基本方法,最常用的就是offer和poll方法。
boolean offer(E o); // 入队 - 新元素添加到队尾
E poll(); // 出队 - 获取队头元素,并将其从队列删除
E remove(); // 删除 - 获取队头元素,并将其从队列删除。如果队列为null,调用该方法会报错。
E peek(); // 获取队列头元素 - 获取队头元素,但不出队
E element(); // 获取队列头元素 - 获取队头元素,但不出队。如果队列为null,调用该方法会报错。PriorityQueue
无界优先级队列,基于优先级堆即平衡二叉堆实现。插入元素时会根据指定的比较器对元素进行排序或者根据元素自带的比较方法进行排序。该队列不允许插入null值,也不允许插入未实现comparable接口的元素。
堆排序算法(选择排序的一种,时间复杂度O(nlogn),不是???稳定排序???): 堆本质是一种数组对象,也是采用二叉树结构性质,规则:任意叶子节点都小于(或大于)它所有父节点,父节点左右孩子大小无要求。
堆排序根据这个规则分为大顶堆(父节点大于子节点,根节点最大)和小顶堆(父节点小于子节点,根节点最小)。
将堆的节点按层进行编号,然后将这种编号顺序映射到数组中。
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
堆排序分为两个步骤: 1)构建堆:从非叶子节点开始遍历,判断是否小于孩子节点,小于就跟最大的叶子节点交换位置。然后从这个新的位置继续迭代判断大小。直到遍历到根节点。遍历完成后就建立起了一个堆。但是左右孩子的顺序还是无序的,所以要做第二步排序步骤。 2)排序:从根节点开始,将根节点与最后一个叶子节点交换位置,然后构建堆。堆构建完成后再将根节点与倒数第二个叶子节点交换位置,然后再次构建堆。直接所有节点都交换完位置,就在就对堆进行了一次排序。
注意该类是在java.util包下,不是并发包内的,所以不是线程安全的,未做任何同步操作。
private static final int DEFAULT_INITIAL_CAPACITY = 11; // 队列默认容量大小
private transient Object[] queue; // 实际是存储在数组里面的
private final Comparator<? super E> comparator; // 元素比较器,如果为指定就默认使用元素自带的比较实现
private transient int modCount = 0; // 记录队列修改操作记录次数
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity + 1]; // 初始化的时候实例化队列数组
this.comparator = comparator;
}
// 入队
public boolean offer(E o) {
if (o == null)
throw new NullPointerException();
modCount++;
++size;
if (size >= queue.length)
grow(size); // 扩容
queue[size] = o; // 插入的时候先直接加入到数组末尾,然后再进行平衡调整
fixUp(size); // 调整堆
return true;
}
// 获取队列头元素
public E peek() {
if (size == 0)
return null;
return (E) queue[1]; // 即堆根节点元素???默认把最小值放在queue[1],为什么呢?稍后看看
}
// 出队 -- 这个堆排序算法先看一下
public E poll() {
if (size == 0)
return null;
modCount++;
E result = (E) queue[1]; // 队列头元素即最小值都存储在queue[1]
queue[1] = queue[size];
queue[size--] = null; // Drop extra ref to prevent memory leak
if (size > 1)
fixDown(1);
return result;
}
// 扩容
private void grow(int index) {
int newlen = queue.length;
if (index < newlen) // don't need to grow
return;
if (index == Integer.MAX_VALUE)
throw new OutOfMemoryError();
while (newlen <= index) {
if (newlen >= Integer.MAX_VALUE / 2) // avoid overflow
newlen = Integer.MAX_VALUE;
else
newlen <<= 2;
}
Object[] newQueue = new Object[newlen];
System.arraycopy(queue, 0, newQueue, 0, queue.length); // 也是通过System.arraycopy来拷贝数组的
queue = newQueue;
}
// 调整堆 ???是使用什么算法调整的??? 好像是堆排序,要不然怎么说是基于堆实现的。对对对就是堆排序
private void fixUp(int k) {
if (comparator == null) { // 如果没有指定比较器,就使用元素自带的比较器进行平衡调整
while (k > 1) {
int j = k >> 1; // 找到数组的中间下标 元素
if (((Comparable<E>)queue[j]).compareTo((E)queue[k]) <= 0) // 如果新插入的元素比中间元素小,不用调整
break;
Object tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp; // 否则的话交换位置
k = j; // 这个排序算法很熟悉 ??????类似快排,选择中间元素为基数。也有可能是堆排序。后面研究下。
}
} else {
while (k > 1) {
int j = k >>> 1;
if (comparator.compare((E)queue[j], (E)queue[k]) <= 0)
break;
Object tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
k = j;
}
}
}
// 降级
private void fixDown(int k) {
int j;
if (comparator == null) {
while ((j = k << 1) <= size && (j > 0)) {
if (j<size &&
((Comparable<E>)queue[j]).compareTo((E)queue[j+1]) > 0)
j++; // j indexes smallest kid
if (((Comparable<E>)queue[k]).compareTo((E)queue[j]) <= 0)
break;
Object tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
k = j;
}
} else {
while ((j = k << 1) <= size && (j > 0)) {
if (j<size &&
comparator.compare((E)queue[j], (E)queue[j+1]) > 0)
j++; // j indexes smallest kid
if (comparator.compare((E)queue[k], (E)queue[j]) <= 0)
break;
Object tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
k = j;
}
}
}ConcurrentLinkedQueue
JDK提供了两种线程安全的队列:
- BlockingQueue 基于锁的阻塞队列
- ConcurrentLinkedQueue 基于CAS的非阻塞队列
我们来看下基于CAS如何实现一个线程安全的队列
代码结构
提供了一个Node静态内部类,Node有一个next指针,以及外部类中定义了head和tail两个指针,从这里可以看出ConcurrentLinkedQueue是一个单向链表的存储结构。
构造函数
提供了一个空的构造函数
成员变量
哨兵(sentinel)节点是一个Dummy Node,可以简化边界条件。很多基于链表的场景中都会临时创建一个Dummy Node。
两个volatile节点:
- volatile Node
head = new Node (null, null); - volatile Node
tail = head;
这里创建了一个空节点,即Dummy Node,head和tail都指向这个空节点。
offer
ConcurrentLinkedQueue是非阻塞队列,所以只提供非阻塞的offer和poll方法入队和出队。
主要逻辑:
- 创建一个Node
- 获取tail节点
- 获取tail节点的next指向,如果next为null,将next指向node(4步骤请看这里,被我插入了),再将tail执行node,结束插入,返回true;
- 如果tail的next不为null,说明有另一个线程执行了插入,本次循环放弃插入,将tail执行next,重入执行插入流程(回到步骤2)。
说明:即使步骤3,next为null(多个线程都检查为null),将next指向node(多个线程都执行这行代码),因为这是原子操作,所以最终也只会只要一个线程更新成功,其它线程都失败。
public boolean offer(E o) {
if (o == null) throw new NullPointerException();
// 1. 创建一个Node
Node<E> n = new Node<E>(o, null);
// 2. for循环,自旋
for(;;) {
Node<E> t = tail; // 获取tail节点 -- tail节点执行最后一个节点
// tail.next?是null吗(这里是单向链表,所以tail不会循环指向head)?
Node<E> s = t.getNext(); // tail.next 正常返回null,好像如果是多线程并发情况下,tail.next 可能指向另一个线程已插入的新元素
if (t == tail) {
if (s == null) {
// --- 这里是单线程执行情况 ---
// 如果 s == null 说明到目前没有并发
if (t.casNext(s, n)) { // 将tail.next指向新的节点n // 如果这时候s被其它线程插入了,就会插入失败。
casTail(t, n); // 再将tail执行n
return true;
}
} else {
// --- 这里是多线程执行情况 ---
// 所以有多线程并发再操作,另一个线程已经插入新值的,所以当前线程就要把这个值插入到其后
casTail(t, s); // 将tail指向s,然后重新执行插入流程
}
}
}
}poll
来看下poll的主要逻辑:
- 取出head.next 第一个节点 first
- 通过CAS将head指向first,如果更新成功,则出队成功;如果更新失败,说明有竞争,重走流程。
public E poll() {
// 1. 也是一个自旋
for (;;) {
Node<E> h = head; // FIFO队列,所以出队,是将头节点出队
Node<E> t = tail;
Node<E> first = h.getNext(); // 获取第一个节点,即head指向的节点
if (h == head) { // 这里又做了一次判断,说明可能执行这一行代码的时候head执行改变了
if (h == t) { // 说明 head.next -> tail 那说明队列是空的,或者已经被另一个线程出队了,导致此时head.next -> tail
if (first == null)
return null; // 直接返回null
else
casTail(t, first); // 将取出来的这个first节点插入入队,将tail指向它。然后结束循环,重新出队
} else if (casHead(h, first)) { // 将head执行first,出队
E item = first.getItem();
if (item != null) {
first.setItem(null);
return item;
}
// else skip over deleted item, continue loop,
}
}
}
}这里总结一下offer和poll方法: ConcurrentLinkedQueue为了确保线程安全,所以每一行代码都有做校验,以至于代码看起来就有点混乱。
Node
Node提供的几个原子操作的方法:
casNext(Node<E> cmp, Node<E> val)修改节点的next指向,将其指向val节点。这里是原子操作,所以当前next必须是指向cmp,才会将其更新为执行val。casItem(E cmp, E val)修改节点的item值,当前item值必须为cmp时,才能修改为val。setItem(E val)直接将item值修改为valsetNext(Node<E> val)直接将next指向修改为val
所以前面两个的更新是有做校验的,后面两个更新是直接更新。
AtomicReferenceFieldUpdater
ConcurrentLinkedQueue使用的CAS是基于AtomicReferenceFieldUpdater进行包装的,将需要原子操作的字段通过工具类进行包装。
- AtomicReferenceFieldUpdater headUpdater 是对head变量的原子包装器
- AtomicReferenceFieldUpdater tailUpdater 是对tail变量的原子包装器
- Node.AtomicReferenceFieldUpdater nextUpdater 是对 Node 的next变量进行的原子包装器
- Node.AtomicReferenceFieldUpdater itemUpdater 是对 Node 的item变量进行的原子包装器
说明这几个变量的更新操作是要确保原子性的,也就意味着这几个变量会存在多线程并发操作的场景。
个人觉得这个工具类适合对已有的对象字段进行原子包装,如果是新的对象可以直接使用Atomic类型即可。
BlockingQueue
阻塞队列接口,扩展了Queue方法,并新增了时间控制。
boolean offer(E o, long timeout, TimeUnit unit) // 入队 - 在指定时间内还未将元素插入队列,则返回false;成功返回true
throws InterruptedException;
E poll(long timeout, TimeUnit unit) // 出队 - 等待一定时间,如果队列为空没有任何元素,则返回null
throws InterruptedException;
E take() throws InterruptedException; // 出队 - 一直等待ArrayBlockingQueue
基于数组的有界阻塞队列(数组可以循环使用),提供FIFO先进先出机制。适合场景比如生产者和消费者问题等。
与LinkedBlockingQueue区别和应用场景 1)都适用于生产者和消费者模式,当队列为空,消费者线程被阻塞;当队列装满,生产者线程被阻塞。 2)ArrayBlockingQueue使用一把锁,LinkedBlockingQueue使用两把锁。内部都是使用ReentrantLock和condition保证生产和消费的同步。
private final E[] items; // 内部是基于数组存储的
private transient int takeIndex; // 下一个出队的数组下标
private transient int putIndex; // 下一个入队的数组下标
private int count; // 队列长度
private final ReentrantLock lock; // 读写等操作加锁 ???为什么使用一把锁而不是两把???
private final Condition notEmpty; // 告诉其它等待读的线程,队列里面有值了
private final Condition notFull; // 告诉其它等待写的线程,队列里面有空位了
final int inc(int i) {
return (++i == items.length)? 0 : i; // 循环,会用count进行比较,等于count就不允许入队
}
// 入队
public boolean offer(E o) {
if (o == null) throw new NullPointerException();
final ReentrantLock lock = this.lock; // 获取对象锁
lock.lock(); // 加锁
try {
if (count == items.length) // 如果队列满,返回false
return false;
else {
insert(o); // 入队
return true;
}
} finally {
lock.unlock(); // 释放锁
}
}
// 入队 - 等待一定时间
public boolean offer(E o, long timeout, TimeUnit unit)
throws InterruptedException {
if (o == null) throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 加锁,该锁可以被打断
try {
long nanos = unit.toNanos(timeout);
for (;;) { // 这里为什么要无限循环呢?因为即使notFull被唤醒,也不能保证一定能插入成功,所以在指定时间内会一直尝试。
if (count != items.length) { // 如果队列未满,直接插入,结束返回true
insert(o);
return true;
}
if (nanos <= 0) // 如果队列满了,且时间小于0直接返会false,插入失败
return false;
try {
nanos = notFull.awaitNanos(nanos); // 否则还有时间,进入等待,等待指定时间或者被其它线程唤醒。
// 如果到了指定时间nanos,且notFull信号变量未被其它线程唤醒,awaitNanos就会返回0或负数。
} catch (InterruptedException ie) {
notFull.signal(); // propagate to non-interrupted thread
throw ie;
}
}
} finally {
lock.unlock();
}
}
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal(); // 信号变量,如果有其他线程阻塞在读操作,那么它们将会接收到这个信号,表示队列有已元素可以读了。
}
// 出队
public E poll() {
final ReentrantLock lock = this.lock; // 获取锁
lock.lock(); // 加锁
try {
if (count == 0)
return null;
E x = extract();
return x;
} finally {
lock.unlock(); // 释放锁
}
}
// 出队 - 等待一定之间
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
long nanos = unit.toNanos(timeout);
for (;;) {
if (count != 0) {
E x = extract();
return x;
}
if (nanos <= 0)
return null;
try {
nanos = notEmpty.awaitNanos(nanos);
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
}
} finally {
lock.unlock();
}
}
// 出队 - 一直等待
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == 0) // 无限循环等待
notEmpty.await();
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
E x = extract();
return x;
} finally {
lock.unlock();
}
}
private E extract() {
final E[] items = this.items;
E x = items[takeIndex]; // 获取元素
items[takeIndex] = null; // 将队列中该下标的指针置为null
takeIndex = inc(takeIndex);
--count;
notFull.signal(); // 通知其他线程,队列里面有空位了
return x;
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = (E[]) new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}这里再来补充一下:
- put/offer 入队,take/poll 出队
- put/take 操作阻塞,offer/poll 操作立即返回 不阻塞
put/take 阻塞
put入队操作主要逻辑:
- 加锁(ArrayBlockingQueue只有一把锁)
- 如果队列满,notFull.await() 进入等待,释放锁
- 否者 insert(o) 入队
- 释放锁
take出队操作主要逻辑:
- 加锁(与put是同一把锁 lock)
- 如果队列空,notEmpty.await() 进入等待,释放锁
- 出队 extract()
- 释放锁
offer/poll 非阻塞
offer入队操作主要逻辑:
- 加锁
- 如果队列满,直接返回false(就这里实现与put不同,put是await等待,offer是立即返回)
- insert 入队
- 释放锁
poll出队操作主要逻辑:
- 加锁
- 如果队列空,立即返回null(这里与take操作不同,take是await等待,poll是直接返回null)
- extract() 出队
- 释放锁
小结:这里只是浅显的分析了下blockingqueue的主要四个方法,是如何实现的。还缺了两个带时间的,我们补上。
offer/poll timeout
offer(timeout)入队的主要逻辑:
- 加锁
- for(;;) 有一个死循环
- 如果队列不满,直接入队 insert 并返回true;
- 如果timeout <= 0,即不等待,结束循环,就直接返回false
- 否则 notFull.awaitNanao(nanos) 使用条件变量等待timeout时长
- timeout时间到后,for 循环重新走一遍流程
poll(timeout)出队的主要逻辑:
- 实现逻辑与offer(timeout)一模一样这里不再分析
小结:offer/poll timeout 方法与无参加的方法执行逻辑一模一样,唯一区别就是 timeout 方法使用 await(timeout) 来实现超时等待。
LinkedBlockingQueue
基于链表的阻塞队列,,提供FIFO先进先出机制。
static class Node<E> { // 链表节点结构
volatile E item;
Node<E> next;
Node(E x) { item = x; }
}
private transient Node<E> head; // 链表头
private transient Node<E> last; // 链表尾
private final ReentrantLock takeLock = new ReentrantLock(); // 出队入库分别使用两把锁,ArrayBlockingQueue使用一把
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition();
private final Condition notFull = putLock.newCondition();
// 入队
public void put(E o) throws InterruptedException {
if (o == null) throw new NullPointerException();
int c = -1;
final ReentrantLock putLock = this.putLock; // 获取写锁
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
try {
while (count.get() == capacity) // 如果队列满,则一直等待
notFull.await();
} catch (InterruptedException ie) {
notFull.signal(); // propagate to a non-interrupted thread ???为什么两次提醒???
throw ie;
}
insert(o); // 入队
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal(); // 告诉其它线程,队列还有空位
} finally {
putLock.unlock(); // 释放锁
}
if (c == 0)
signalNotEmpty();
}put/take 阻塞
put入队操作主要逻辑:
- putLock加锁(LinkedBlockingQueue有两把锁,putLock和takeLock)
- 如果队列满,notFull.await() 进入等待,释放锁
- 否者 insert(o) 入队
- 队列数量+1(这里 count 使用的是AtomicInteger类型,因为LinkedBlockingQueue可以同时有两个线程来操作队列,所以count要确保线程安全)
- 释放锁
take出队操作主要逻辑:
- takeLock加锁
- 如果队列空,notEmpty.await() 进入等待,释放锁
- 出队 extract()
- 队列数量-1(count.getAndDecrement)
- 释放锁
小结:这里不能按ArrayBlockingQueue的思路来分析LinkedBlockingQueue,LinkedBlockingQueue是两把锁,我们要从条件变量的唤醒了分析。
putLock/takeLock
首先从锁的性质来看,这两个把锁都是独占锁,所以同一时间只能有一个线程put,一个线程take。
putLock,成功获取锁并入队后,会判断下队列的容量是否还可以继续入队,如果可以,则会唤醒同样还在排队的putLock线程。
一把锁的时候,是由另一方出队后才通知我们的;现在有两个锁,同一把锁会互相通知。
PriorityBlockingQueue
线程安全的PriorityQueue,内部引用PriorityQueue实例,对操作加锁。
private final PriorityQueue<E> q;
private final ReentrantLock lock = new ReentrantLock(true);
private final Condition notEmpty = lock.newCondition();
public PriorityBlockingQueue() {
q = new PriorityQueue<E>(); // 内部实例化PriorityQueue
}
// 入队
public boolean offer(E o) {
if (o == null) throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
try {
boolean ok = q.offer(o);
assert ok; // 这里使用了1.5新做的assert断言
notEmpty.signal(); // 插入成功后,通知其他等待线程队里有值了
return true;
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // take操作都是可打断的锁
try {
try {
while (q.size() == 0)
notEmpty.await();
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
E x = q.poll();
assert x != null;
return x;
} finally {
lock.unlock();
}
}
// 出队 就是在原有PriorityQueue操作上加锁保证线程安全
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return q.poll();
} finally {
lock.unlock();
}
}SynchronousQueue
这是一个没有容量的队列,所有PUT操作都要等有TAKE操作才能执行,反之亦然。提供FIFO或LIFO两种模式的同步队列。一个线程调用PUT操作必须等待直到有另一个线程调用TAKE操作,才能成功插入数据返回。另一个线程调用TAKE操作必须等待直到有一个线程调用了PUT操作才能成功获取到数据返回。
/** Lock protecting both wait queues */
private final ReentrantLock qlock;
/** Queue holding waiting puts */
private final WaitQueue waitingProducers;
/** Queue holding waiting takes */
private final WaitQueue waitingConsumers;
public SynchronousQueue(boolean fair) {
if (fair) { // fair 决定使用FIFO还是LIFO
qlock = new ReentrantLock(true);
waitingProducers = new FifoWaitQueue(); // FIFO
waitingConsumers = new FifoWaitQueue();
}
else { // 默认 false
qlock = new ReentrantLock();
waitingProducers = new LifoWaitQueue(); // LIFO
waitingConsumers = new LifoWaitQueue();
}
}
static abstract class WaitQueue implements java.io.Serializable {
/** Create, add, and return node for x */
abstract Node enq(Object x);
/** Remove and return node, or null if empty */
abstract Node deq();
}
/**
* FIFO queue to hold waiting puts/takes.
*/
static final class FifoWaitQueue extends WaitQueue implements java.io.Serializable {
private static final long serialVersionUID = -3623113410248163686L;
private transient Node head;
private transient Node last;
Node enq(Object x) {
Node p = new Node(x);
if (last == null)
last = head = p;
else
last = last.next = p;
return p;
}
Node deq() {
Node p = head;
if (p != null) {
if ((head = p.next) == null)
last = null;
p.next = null;
}
return p;
}
}
/**
* LIFO queue to hold waiting puts/takes.
*/
static final class LifoWaitQueue extends WaitQueue implements java.io.Serializable {
private static final long serialVersionUID = -3633113410248163686L;
private transient Node head;
Node enq(Object x) {
return head = new Node(x, head);
}
Node deq() {
Node p = head;
if (p != null) {
head = p.next;
p.next = null;
}
return p;
}
}
public void put(E o) throws InterruptedException {
if (o == null) throw new NullPointerException();
final ReentrantLock qlock = this.qlock;
for (;;) {
Node node;
boolean mustWait;
if (Thread.interrupted()) throw new InterruptedException();
qlock.lock(); // 加锁
try {
node = waitingConsumers.deq(); // 从消费队列取出一个元素
if ( (mustWait = (node == null)) ) // 如果消费队列没有元素,将新元素插入生产者队列
node = waitingProducers.enq(o);
} finally {
qlock.unlock(); // 释放锁
}
if (mustWait) {
node.waitForTake();
return;
}
else if (node.setItem(o))
return;
// else consumer cancelled, so retry
}
}DelayQueue
延迟队列,队列中的元素到期了才能POLL出来。
private transient final ReentrantLock lock = new ReentrantLock();
private transient final Condition available = lock.newCondition();
private final PriorityQueue<E> q = new PriorityQueue<E>();
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E first = q.peek();
if (first == null || first.getDelay(TimeUnit.NANOSECONDS) > 0)
return null; // 元素未到期,不会出队
else {
E x = q.poll();
assert x != null;
if (q.size() != 0)
available.signalAll();
return x;
}
} finally {
lock.unlock();
}
}Concurrent
并发包,里面包含了集合框架的并发解决方案
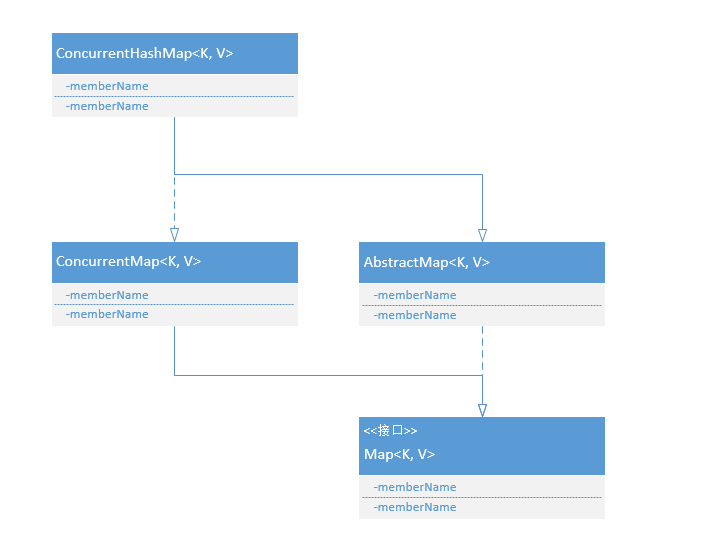
ConcurrentHashMap
线程安全的HashMap。实现了ConcurrentMap接口,ConcurrentMap接口新增了一些原子操作方法,putIfAbsent、remove、replace等。
rehash ConcurrentHashMap扩容不会增加Segment的数量,而只会增加Segment中链表数组的容量大小。
ConcurrentMap
// 插入键值对元素时,如果键在map中不存在,则新增键值对;否则获取键在map中的值并返回值。
V putIfAbsent(K key, V value);
// 只有当key和value都在map中存在时才会进行删除,删除成功后返回true,否则不执行删除操作直接返回false。
boolean remove(Object key, Object value);
// 只有当key和value都在map中存在时才会进行替换,替换成功后返回true;否则直接返回false。
boolean replace(K key, V oldValue, V newValue);
// 只有当key在map中存在时才会更新value并返回新的value值,否则返回null。
V replace(K key, V value);ConcurrentHashMap
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
final Segment[] segments; // 每个segment对象就是一个Entry table[]数组,ConcurrentHashMap将数组再分为为几个段
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}
// get,put实际操作都封装在Segment
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry[] table; // 每个segment都有一个Entry数组
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
// put操作和hashmap的一样,只是在操作前加了锁,以及操作后释放锁
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); // 加锁
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry[] tab = table; // put 操作跟hashmap一样
int index = hash & (tab.length - 1);
HashEntry<K,V> first = (HashEntry<K,V>) tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock(); // 解锁
}
}
// segment内的rehash操作,不是整个segment数组rehash。???segment数组好像不会rehash或者调整容量???
void rehash() {
HashEntry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity >= MAXIMUM_CAPACITY)
return;
HashEntry[] newTable = new HashEntry[oldCapacity << 1];
threshold = (int)(newTable.length * loadFactor);
int sizeMask = newTable.length - 1;
for (int i = 0; i < oldCapacity ; i++) { // rehash是在put操作时发生的,put已加锁,所以rehash线程安全
// We need to guarantee that any existing reads of old Map can
// proceed. So we cannot yet null out each bin.
HashEntry<K,V> e = (HashEntry<K,V>)oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
// Single node on list
if (next == null)
newTable[idx] = e;
else {
// Reuse trailing consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone all remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
int k = p.hash & sizeMask;
HashEntry<K,V> n = (HashEntry<K,V>)newTable[k];
newTable[k] = new HashEntry<K,V>(p.key, p.hash,
n, p.value);
}
}
}
}
table = newTable;
}
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = new Segment[ssize];
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);
}
// ConcurrentHashMap 对外提供的get方法,内部实际调用segment的get方法
public V get(Object key) {
int hash = hash(key); // throws NullPointerException if key null
return segmentFor(hash).get(key, hash); // 根据segment获取key
}
// ConcurrentHashMap 对外提供的put方法,内部实际调用segment的put方法
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, false);
}
final Segment<K,V> segmentFor(int hash) {
return (Segment<K,V>) segments[(hash >>> segmentShift) & segmentMask]; // 根据key的hash查找在segments数组的位置下标
}
// size方法返回map的元素数量,需要统计每个segment的table数量。
public int size() {
final Segment[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) { // 会尝试两次
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count;
if (mc[i] != segments[i].modCount) { // 因为在统计过程中,集合很可能会被修改
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // size方法会把所有segment都加锁,然后再进行统计,统计完了再一一个释放锁。
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
}
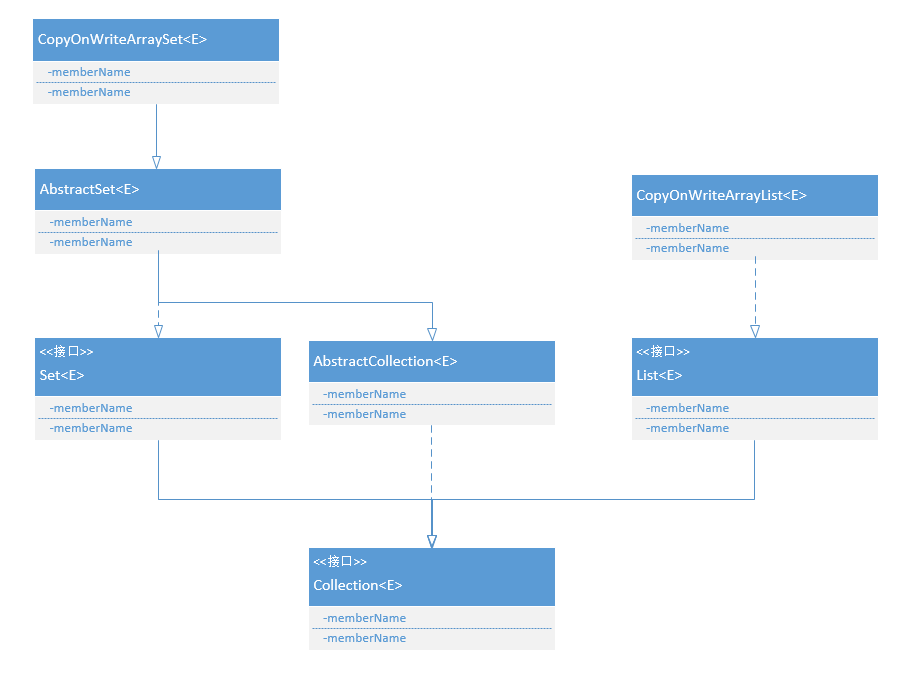
}CopyOnWriteArrayList
线程安全的ArrayList,写操作同步并且每次写都会新创建一个数组,读操作支持并发读的是旧的数组。所以对于写少读多的场景适合,且是一个线程安全的列表。ArrayList线程不安全的,所以读效率是一样的,但是并发写会出问题。
private volatile transient E[] array;
public CopyOnWriteArrayList() {
array = (E[]) new Object[0]; // 初始化的时候创建了一个容量为1的数组
}
// 添加元素到列表中,该方法是同步的
public synchronized boolean add(E element) {
int len = array.length;
E[] newArray = (E[]) new Object[len+1]; // 创建了一个新的数组,每次add的时候都扩容一次
System.arraycopy(array, 0, newArray, 0, len);
newArray[len] = element;
array = newArray; // array指向新的数组
return true;
}
// 将元素添加到指定位置
public synchronized void add(int index, E element) {
int len = array.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+", Size: "+len);
E[] newArray = (E[]) new Object[len+1]; // 创建新的数组
System.arraycopy(array, 0, newArray, 0, index); // 将指定位置前的元素拷贝到新数组
newArray[index] = element; // 将元素添加到指定位置
System.arraycopy(array, index, newArray, index+1, len - index); // 将指定位置后的元素拷贝到新数组
array = newArray;
}
// 获取指定位置的元素
public E get(int index) {
E[] elementData = array(); // 添加对数组的引用,这时候如果有add操作,add是新创建一个数组,所以这里不会冲突。
rangeCheck(index, elementData.length);
return elementData[index];
}write的逻辑:
- 加锁;
- 创建一个新的数组 length+1
- 将旧数组拷贝到新数组 System.arraycopy
- 将新值放入数组末尾
- 新数组替换旧数组
小结:
- write操作是直接使用同步方法 synchronized 来保证线程安全的;
- read操作无锁
说明:JDK 1.6 后 CopyOnWriteArrayList改用ReentrantLock来保证线程安全了,去掉了同步方法。
再说明:CopyOnWrite这里的Write不是说只有在新增元素的时候才同步,这里的write是指对集合的修改操作,所以remove/clear操作(subList也同步了)也需要同步。
subList也同步了,这里很有意思,subList返回的是一个COSSubList,里面的所有方法都同步了!有时间再来看看。
public synchronized E remove(int index) {
int len = array.length;
rangeCheck(index, len);
E oldValue = array[index];
E[] newArray = (E[]) new Object[len-1];
System.arraycopy(array, 0, newArray, 0, index);
int numMoved = len - index - 1;
if (numMoved > 0)
System.arraycopy(array, index+1, newArray, index, numMoved);
array = newArray;
return oldValue;
}Atomic
AtomicInteger
AtomicInteger
private static final Unsafe unsafe = Unsafe.getUnsafe(); // 使用unsafe实例的cas方法来更新值
private volatile int value; // 实际存储int值
public AtomicInteger(int initialValue) {
value = initialValue; // 实例化的时候,将值保存到value
}
public final int get() {
return value; // get返回value值
}
// 将值更新为newValue,并返回oldValue
public final int getAndSet(int newValue) {
for (;;) {
int current = get();
if (compareAndSet(current, newValue))
return current;
}
}
// 获取当前值并+1
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
// 更新值,如果current当前值为expect,则更新为update值,并返回true;否则不更新直接返回false
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update); // 调用unsafe实例提供的方法cas
}AtomicReference
private static final Unsafe unsafe = Unsafe.getUnsafe();
private volatile V value;
public AtomicReference(V initialValue) {
value = initialValue;
}
public final boolean compareAndSet(V expect, V update) {
return unsafe.compareAndSwapObject(this, valueOffset, expect, update);
}
public final V getAndSet(V newValue) {
while (true) {
V x = get();
if (compareAndSet(x, newValue))
return x;
}
}CAS
CAS存在问题:
- ABA问题
AtomicStampedReference可以对引用进行判断
- 循环开销问题
循环一段时间最后能暂停一会
- 无法应用到多个共享变量
AtomicReference可以直接操作对象
AtomicReferenceFieldUpdater
工具类的作用:可以将对象的volatie字段进行原子更新,底层通过反射实现。
必须要是volatile修饰的字段,否则会抛异常
这样多线程要同时更新对象的一个字段时,可以使用这个工具类来更新,确保原子性,避免出现问题。它在更新前会确保旧值是正常的,才会进行更新。
那这个工具类底层又是如何实现的呢?
初步是为这个字段提供了原子包装器。
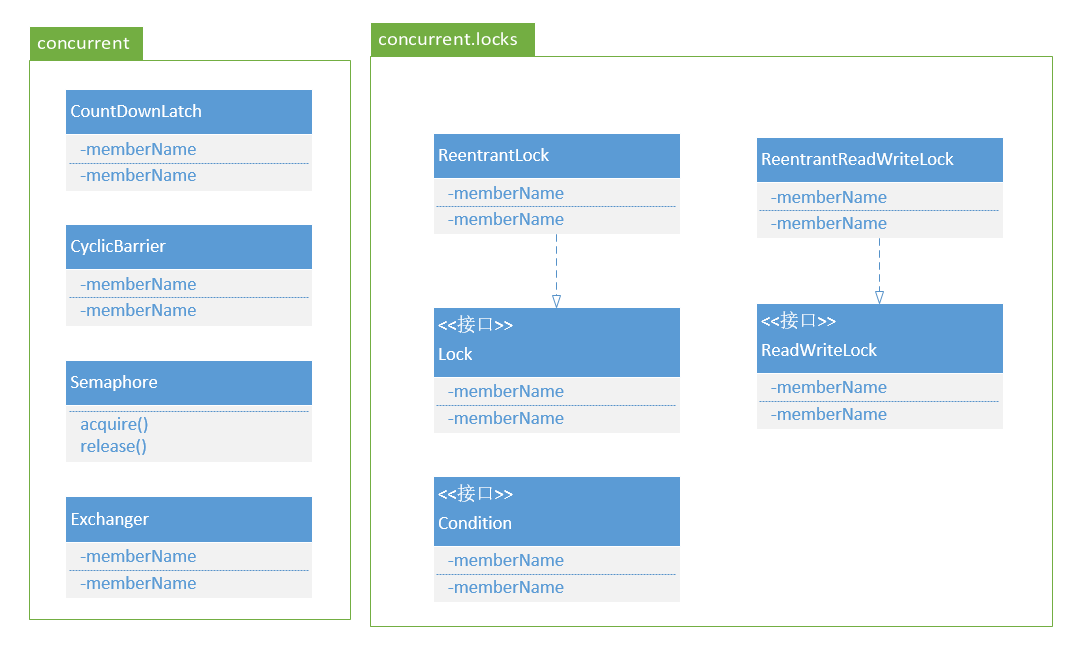
Lock
互斥性,允许多个线程同时对数据进行读操作,但是同一时间内只允许一个线程对数据进行写操作。通常将锁分为共享锁和排它锁,也叫读锁和写锁。Java中提供多种方式保证互斥性,最简单方式是使用Synchronized。
原子性,对数据的操作是独立不可分割的。保证原子性最简单的方式是使用操作系统指令,一次操作对应一条操作系统指令。最常见的方式是加锁,如Synchronized和Lock。除了锁之外,还有一种方式是CAS(Compare And Swap),即修改数据之前先比较与之读取到的值是否一致,如果一致则修改,否则重新执行,这也是乐观锁的实现原理。有些场景不一定有效,比如另一线程先修改了某个值,然后再改回原来值,CAS就无法判断了。
有序性,对指令做重排序。 1)编译器优化的重排序,编译器在不改变单线程程序语义的前提下,重新安排语句的执行顺序。 2)指令级并行的重排序,现代处理器采用指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。 3)内存系统的重排序,处理器使用缓存,使得加载和存储操作看上去可能是乱序执行。
管程(Monitor)
在操作系统原理中,用信号量能解决并发问题。Java 在 1.5 之前仅仅提供了 synchronized 关键字及 wait()、notify()、notifyAll() 这三个方法解决并发问题,并没有提供信号量。
Java 采用的是管程技术,synchronized 关键字及 wait()、notify()、notifyAll() 这三个方法都是管程的组成部分。而管程和信号量是等价的,所谓等价指的是用管程能够实现信号量,也能用信号量实现管程。但是管程利用OOP的封装特性解决了信号量在工程实践上的复杂性问题,因此java采用管理机制。
管程,对应的英文是 Monitor,Java领域直译为“监视器”。所谓管程,指的是管理共享变量以及对其操作过程,让它们支持并发访问。翻译为 Java 领域的语言,就是管理类的成员变量和成员方法,让这个类是线程安全的。
MESA模型
在管程的发展史上,先后出现过三种不同的管程模型,分别是:Hasen 模型、Hoare 模型和 MESA 模型。其中,现在广泛应用的是 MESA 模型,并且 Java 管程的实现参考的也是 MESA 模型。
在并发编程领域,有两大核心问题:一个是互斥,即同一时刻只允许一个线程访问共享资源;另一个是同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。
管程处理互斥
管程解决互斥问题的思路很简单,就是将共享变量及其对共享变量的操作统一封装起来。互斥依赖于锁。
管程处理同步
在管程模型里,共享变量和对共享变量的操作是被封装起来的,当多个线程同时试图进入管程内部时,只允许一个线程进入,其他线程则在入口等待队列中等待。这样我们就能保证对共享变量的互斥访问。
管程里还引入了条件变量的概念,而且每个条件变量都对应有一个等待队列。
那条件变量和等待队列的作用是什么呢?其实就是解决线程同步问题。当进入管程的线程发现关注的变量不满足的时则进入等待队了,等关注的变量满足时则从等待队列中出来,继续执行。因此,管程的特点是一条件、两队列。
总结
Java 参考了 MESA 模型,语言内置的管程(synchronized)对 MESA 模型进行了精简。MESA 模型中,条件变量可以有多个,Java 语言内置的管程里只有一个条件变量。
Java 内置的管程方案(synchronized)使用简单,synchronized 关键字修饰的代码块,在编译期会自动生成相关加锁和解锁的代码,但是仅支持一个条件变量;而 Java SDK 并发包实现的管程支持多个条件变量,不过并发包里的锁,需要开发人员自己进行加锁和解锁操作。
并发编程里两大核心问题——互斥和同步,都可以由管程来帮你解决。
Synchronized
Synchronized 1)确保线程互斥的访问同步代码 2)保证共享变量的修改能够及时可见 3)有效解决重排序问题
都是通过持有monitor对象实现。每个对象都有一个监视器锁,每个类也对应一个Monitor。
Synchronized代码块同步 monitorenter和monitorexit指令 实现原理:每个对象都有一个监视器锁(monitor),当monitor被占用就会处于锁定状态,线程执行monitorenter指令尝试获取锁。如果线程已占用monitor,可以重新获取进去,monitor数量加1。如果其他线程占有monitor,则该线程进去阻塞状态,直到monitor数量为0,再重新尝试获取monitor。monitorexit指令只有monitor的拥有者线程才可以执行,monitor数量减一。wait/notify也是使用monitor对象实现的。
Synchronized方法同步 实现原理:方法同步并没有使用monitorenter和monitorexit指令,而是通过常量池中方法的ACC_SYNCHRONIZED标示符来实现的。方法调用先检查该标志是否被设置,被设置了,执行线程需先获取monitor,获取成功后才能执行方法,执行完后再是否monitor。
monitor监视器锁,底层又是依赖操作系统的Mutex Lock来实现的。Mutex Lock称为“重量级锁”,效率低。所以JDK对Synchronized进行优化,引入了“轻量级锁”和“偏向锁”。
轻量级锁和偏向锁
锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,状态会升级,但是是单向升级,只能低到高,不能降级。JDK1.6默认开启偏向锁和轻量级锁。-XX:-UserBiasedLocking 关闭偏向锁。锁对象保存在对象的头文件中。
轻量级锁,在没有多线程竞争的情况下,减少传统重量级锁产生的性能消耗。适用线程交替执行同步块的情况,同步块执行速度非常快。 偏向锁,在无多线程竞争的情况下,减少不必要的轻量级锁执行路径。适用只有一个线程执行同步块。轻量级锁获取释放需要依赖多次CAS原子指令,偏向锁只依赖一次CAS。
偏向锁 加锁:线程第一次进入同步块,CAS更新对象的Mark Word(偏向锁标志位为“1”,记录线程的ID) 释放:当有另一个线程来竞争锁时,就不再使用偏向锁,升级为轻量级锁。拥有偏向锁的线程不会主动释放锁,每次执行同步代码的时候直接判断偏向线程ID是否等于自己ID,等于就执行代码;不等于就说明有竞争了。
轻量级锁 1)每次退出同步块释放锁,偏向锁只有在发生竞争时才释放锁。 2)每次进入和退出都需要CAS更新对象头。 3)竞争锁失败时,适应性自旋尝试抢占锁。
其他锁优化手段 1)锁粗化,同一系列操作会反复对同一把锁进行上锁和解锁操作,编译器会扩大锁的边界,从而只使用一次上锁和解锁。 2)锁清除,代码块中没有涉及共享数据,编译器会清除锁。 3)自旋锁,锁竞争失败线程会被挂起、阻塞都要被转入内核态,进行上下文切换。自旋线程竞争失败时并不会立即进去阻塞状态,而会继续持有CPU执行一段时间,效率高,但会造成CPU资源浪费。
ReentrantLock
独占锁,实现了Lock接口,内置Sync、FairSync、NonfairSync内部类,基于AQS实现。lock方法通过调用内部Sync对象的lock方法实现,tryLock方法调用Sync对象的tryAcquire方法,unlock方法调用Sync对象的release方法。所以这里主要是分析Sync类的内部实现。
ReentrantLock默认使用NofairSync非公平锁。
Sync抽象类继承了AQS,FairSync公平锁,NofairSync非公平锁分别为Sync的实现类。
公平锁就是在锁上等待时间最长的线程将获得锁的使用权。
ReentrantLock和Synchronized的区别:
- Synchronized自动加解锁,ReentrantLock手动加解锁;
- Synchronized不可中断,ReentrantLock可中断;
- 两个都是可重入锁,但是ReentrantLock重入获取锁次数必须与释放锁一样;
- Synchronized是非公平锁,ReentrantLock默认非公平锁,也支持公平锁。
AQS是JDK中为“线程同步”提供的一套基础工具类,基于AQS可以实现Java中的非常多“锁”,ReentrantLock就是基于AQS实现的可重入锁。
可重入锁是指同一个线程可以多次获取已获取到的锁。
FairSync公平锁的lock实现,当发现没有线程持有锁,不会立马去占有锁,而是会先去等待队列中查询是否有线程在等待锁,如果有,则将其唤醒,并将当前线程加入等待队列中。
源码分析
先从代码结构来看,有三个静态内部类
- Sync 从名字可以看出,也是基于AQS实现的锁
- NonfairSync 继承Sync,实现了非公平锁逻辑,默认非公平锁
- FairSync 继承Sync,实现了公平锁逻辑
成员变量/构造函数
ReentrantLock只要一个Sync sync成员实例变量,在构造函数创建
// 1. 默认非公平锁
sync = new NonfairSync();
// 2. 也可以参数指定
sync = (fair) ? new FairSync() : new NonfairSync();
锁的几个主要方法
来看看ReentrantLock的几个主要方法
- lock/tryLock 加锁
- unlock 释放锁
lock
现在来看下lock的主要逻辑,lock方法直接委派给sync.lock方法。而sync.lock方法是一个抽象方法,由具体子类实现。所以这里默认调用的是NonfairSync.lock方法。
我们还是先来看下Sync这个抽象类的大体逻辑
ReentrantLock.Sync
只要一个成员变量:transient Thread owner 记录当前持有锁的线程。
提供了lock抽象方法:abstract void lock() 具体加锁方法由子类实现。
NonfairSync
现在就看看NonfairSync.lock方法实现:
- 第一次先直接通过CAS尝试去获取资源锁,如果获取成功,owner = Thread.currentThread(),将owner指向自己,直接返回;
- 如果第一次尝试获取资源失败,则调用AQS的acquire方法再次尝试获取资源,如果还是获取失败则进入等待。(这里有一大堆逻辑要分析,稍后见)
AQS正常实现逻辑是acquire成功state+1,release成功state-1,当state==0时,acquire才能成功否则进入等待。
刚刚把AQS的acquire和release两个方法复习了一遍,现在来看看ReentrantLock的Sync是如何实现tryAcquire和tryRelease方法逻辑的。
Sync.tryAcquire方法由子类实现,分别为NonfairSync.tryAcquire和FairSync.tryAcquire这两个方法。
先来看下NonfairSync的tryAcquire方法实现逻辑:
- getState 获取资源数量,如果state == 0,说明资源可用;直接CAS更新state,更新成功,返回true;
- 如果state != 0 说明资源已经被占用,这里会判断下是否是自己占有的 current 是否指向自己,如果是,state再+1,表示重入,然后返回true
- 如果也不是自己占有的,则返回false,进入AQS的代码逻辑
非公平锁的lock实现小结:
- 会直接先通过CAS来更新资源锁,而不走AQS的acquire获取资源逻辑,如果CAS直接更新成功,说明获取资源成功,返回true;
- CAS更新失败,才正常执行acquire逻辑;
- acquire逻辑会先调用tryAcquire的实现,如果tryAcquire获取成功,则直接返回ture;如果tryAcquire获取失败,则将当前线程进入等待队列;
FairSync
现在来看下公平锁的acquire逻辑:
- 直接调用AQS的acquire逻辑
- AQS会先调用子类的tryAcquire逻辑
所以这里分析下FairSync.tryAcquire方法逻辑即可:
- getSate 获取资源数量,如果state == 0,说明资源可用;(这里开始代码的实现与nonfair不同了)
- 如果资源可用,会再判断AQS的等待队列是否有线程再等待 hasQueuedPredecessors(),如果有线程等待,则放弃资源;如果没有,则CAS更新资源;
- 如果state != 0 说明资源已经被占用,这里会判断下是否是自己占有的 current 是否指向自己,如果是,state再+1,表示重入,然后返回true 4 . 如果也不是自己占有的,则返回false,进入AQS的代码逻辑
unlock
前面把的lock逻辑分析完了,现在来看看unlock的逻辑。
代码也是只有一行
sync.release(1); // 释放1个资源
sync没有重写AQS.release方法,所以这里是直接调用AQS.release实现,公平锁和非公平锁的release实现逻辑是一样的
Condition条件变量
Condition
ReentrantLock的newCondition方法,创建了一个AQS.ConditionObject实例。
我们来看下这个ConditionObject的设计
实现了Condition接口
Condition接口定义了主要的四个方法:
- await
- await(timeout)
- signal
- signalAll
成员变量
ConditionObject提供了一个空的构造函数,所以我们直接来看成员变量的设计
两个Node节点:
- Node firstWaiter
- Node lastWaiter
粗略的看了下Node的结构,像是一个双向链表。
现在直接来看ConditionObject是如何实现上面四个方法的
await
await方法,将当前调用线程挂起,进入等待状态,我们来看看是如何实现的
await方法主要逻辑:
- 检查thread是否有中断标识,有则直接抛出中断异常
先停一下,看来要想分析AQS的等待队列了
AQS 队列
这里先说明一下: AQS有两个队列,一个是同步队列,一个是等待队列。
- 同步队列,就是在acquire获取资源失败的线程进入的队列;数据结构使用head、tail,以及prev、next指针来维护;
- 等待队列,就是在Condition.await因为某些条件不满足而进入的队列;数据结构使用firstWaiter、lastWaiter,以及nextWaiter指针来维护。
Condition.await操作前,线程必须要先获取到锁(即当前线程节点是同步队列里的头节点head),才能await释放锁。所以调用await方法,线程释放锁,即将同步队列的head节点加入到等待队列中。
Condition.signal操作,会将等待队列的首节点加入到同步队列中,然后被唤醒,尝试去获取资源。
ReentrantReadWriteLock
这里先抛几个问题:
- read和write lock分别是怎么实现的,read是如何允许多个线程获取资源的,write又是如何只允许一个线程获取资源的,这两个锁会有冲突吗?
- 获取write lock的时候,read还能读吗?
代码结构
现在来看下ReentrantReadWriteLock的代码结构:
- Sync 说明也是基于AQS实现的
- NonfairSync 非公平锁,读写锁也提供了公平和非公平方式
- FairSync 公平锁 以上三个的实现与ReentrantLock类似,接着继续看
- ReadLock 读锁
- WriteLock 写锁
看下提供了哪几个方法,其实就是调用读锁加锁和写锁加锁:
- readLock() 返回 ReentrantReadWriteLock.ReadLock 实例
- writeLock() 返回 ReentrantReadWriteLock.WriteLock 实例
构造函数
那这两个读写锁实例是什么时候创建的?来看下构造函数。
public ReentrantReadWriteLock() {
sync = new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
显然,是在构造函数,即初始化时创建的,同时默认是非公平锁。
那现在就来看下这两个锁的实现,先看读锁
ReadLock
一个Sync成员变量,由构造函数传入,持有的外部类ReentrantReadWriteLock的Sync实例。
来看看lock和unlock方法的实现
先解释下读锁,即共享锁,所以即设计思想应该是可以多个线程获取资源,那资源数state是大于1的。lock永远不会阻塞,同时unlock的时候就会state-1。我们来看看,ReadLock是否是这样实现的。
lock
lock方法就是调用AQS的acquireShared(1)方法,我们知道AQS最终还是调用子类的方法实现。tryAcquireShare方法是在Sync的nonfairTryAcquireShared里实现的,我来看看(先以非公平锁视角来分析)。
主要逻辑:
- 是否超过读锁最大数量限制(读写锁是有数量限制的,这里注意。具体如何判断,下次分析)
- 如果有写锁,且不是自己,则获取失败(重大发现,所以读写锁,读读可以,读写不可以,写写更不可以,但是写读可以)
这里说明,如果你有写锁,你就可以同时获取读锁。
- CAS 更新资源,state+1;(这里要再分析下)
所以小结一下:读锁的加锁过程主要就是判断是否有写锁,如果有写锁则获取失败。
一句话如果没有写锁,读锁就可以获取成功。
unlock
unlock直接调用AQS的releaseShared(1)方法,所以最终实现就是在Sync.tryReleaseShared方法里。
主要逻辑:
- nextc这里先不分析
- CAS 释放资源 state-1
小结:所以读锁的unlock方法很简单,就是state-1.
WriteLock
WriteLock也是有一个Sync成员变量
lock
lock方法是调用sync的wlock方法,sync.wlock是一个抽象方法,最终由NonfairSync.wlock实现。
实现方式跟ReentrantLock几乎一模一样,直接先CAS更新看是否能获取成功,如果成功直接返回;失败,才走正常流程。
主要逻辑:
- compareAndSetState(0, 1) 直接尝试用CAS更新state
- acquire(1) 乖乖走AQS的acquire逻辑
那AQS的acquire逻辑还是会调用tryAcquire,我们再来看看这个方法的实现。在Sync.nonfairTryAcquire里。
主要逻辑:
- 做锁最大数量校验
- CAS 更新值,成功 owner 指向自己,返回true;否者返回false
一句话:写锁是独占锁,只能一个线程获得。
unlock
调用AQS的relaseShared,这里与ReadLock共用tryReleaseShared实现。
这里有一个疑问还没去分析,ReadWriteLock是如何使用AQS的state的?
我们试着来分析一下: ReadLock和WriteLock都是使用Sync,说明它们是共用一个AQS,那state也共用吗?分析源码后发现,AQS.state 是一个int类型,32位。这里ReadLock使用高16位,WriteLock使用低16位。
ReadLock高16位表示持有读锁的线程数量(sharedCount 还记得前面那个65536吗,其实就是这里计算出来的,因为有16位),WriteLock低16位表示写锁重入的次数(exclusiveCount 也是65536)。
state状态值为 0 表示锁空闲,sharedCount不为 0 表示分配了读锁,exclusiveCount 不为 0 表示分配了写锁。
现在对ReadWriteLock来一个阶段性的总结:
AQS
AQS代码结构非常庞大,这里先看最主要的两个方法:acquire
acquire方法用于获取资源,如果获取成功资源数+1,否则当前线程进入等待队列。
AQS.acquire
acquire方法里面主要执行了三个方法:
- tryAcquire() 尝试获取资源,这个方法是一个空实现,具体获取资源逻辑由各子类实现
- addWaiter(Node.EXCLUSIVE) 如果获取资源失败,则进入等待队列;这里创建了一个独占类型的节点,将节点加入等待队列
- acquireQueued() 自旋方式尝试检测资源是否可用
addWaiter方法将当前线程加入等待队列(AQS里的等待队列是一个双向链表,所以每个入队的线程都封装成一个Node节点)
acquireQueued方法for循环自旋等待:
- tryAcquire再次尝试获取锁,如果获取成功,出队,返回;
- 如果获取失败,将自己挂起(使用LockSupport.park()方法),等待中断。线程如果被中断后会再次进入循环尝试获取锁,流程再走一遍。
那现在来看看这个挂起的线程什么时候被唤醒?唤醒的顺序是什么?
AQS.release
也是主要执行了两个方法:
- tryRelease 尝试释放资源,这个方法也是一个空实现,由子类实现具体逻辑。与tryAcquire方法对应,子类可以决定是否成功。
- unparkSuccessor 唤醒等待的线程节点,使用LockSupport.unpark(s.thread) 唤醒指定线程。
唤醒谁?
按FIFO的顺序唤醒队列里的线程节点。这里使用LockSupport来唤醒线程,而不是Condition的await/signal或者Object的wait/notify方法。因为LockSupport可以唤醒指定线程,而Condition和Object只能随机唤醒。
LockSupport的实现原理是什么? JDK 哪个版本提供的?
现在对AQS来一个小结:
- AQS提供了acquire获取资源和release释放资源两个方法;
- 具体acquire获取资源逻辑由子类实现,如果获取资源成功则直接返回;如果获取失败,则执行AQS的入队操作;入队后线程调用LockSupport.park将自己挂起;
- 具体release释放资源逻辑也是由子类失效,如果释放失败则直接返回失败;如果释放成功,则再执行AQS的唤醒操作,等待队列线程出队,并使用LockSupport.unpark方法唤醒线程。被唤醒的线程不会直接获取到资源,一样还是要走获取资源逻辑,去尝试获取锁。
AQS.acquireShare
acquireShare方法里面主要执行两个方法(Share表示共享模式):
- tryAcquireShared() 尝试获取资源,,这个方法是一个空实现,具体获取资源逻辑由各子类实现(这里与tryAcquire方法类似)。
- doAcquireShared() 进入等待队列,也是将线程封装成节点入队;后面的实现就与独占的不一样的(这里的代码下次分析)。
AQS.releaseShare
releaseShare方法也是主要执行两个方法:
- tryReleaseShared() 尝试释放资源,这个方法也是一个空实现,由子类实现具体逻辑。与tryAcquireShare方法对应,子类可以决定是否成功。
- doReleaseShared() 唤醒等待的线程节点
LockSupport
LockSupport的作用也是用于挂起和唤醒线程,它与Condition和Object不同的是,LockSupport可以唤醒指定的线程。
那它是如何唤醒指定线程的呢?现在我们来分析一下
LockSupport的代码结构非常简单,核心的方法是park和unpark。
构造函数是private私有的,所以外部不能实例化LockSupport,且也没有对外提供get方式。那么park和unpark肯定就是静态方法了。
类成员变量
- static final Unsafe unsafe = Unsafe.getUnsafe();
LockSupport只有一个变量,就是unsafe,所以可以推断LockSupport的park和unpark最终是用本地方法实现的。
park
park方法就一行代码
public static void park() {
unsafe.park(false, 0L);
}
直接调用unsafe的park方法
unpark
unpark方法也是只有区区两行代码
public static void unpark(Thread thread) {
if(thread != null) {
unsafe.unpark(thread);
}
}
小结:到这里就是一脸懵逼,因为LockSupport把操作到委托给unsafe了,具体unsafe如何操作我们是看不到的。那我们就来看看代码上的注释说明是如何解释这个工具类的作用的。
首先来看看类上的注释:
- 每一个线程Thread都关联一个permit变量(类似于Semaphore信号量)
- park操作会检查这个permit是否可用,如果可用,permit-1 返回成功继续执行;否则,线程被挂起
- unpark操作会释放permit,表示permit可用,park的线程会被唤醒。但是unpark只会释放一次,且可以在park之前先调用unpark将permit设置为可用,这样park操作就不会挂起了。
注意:park方法没有抛出任何异常,也没有interrupttedException中断异常,所以可以推断LockSupport.park方法不会响应中断的。
CountDownLatch
CountDownLatch也是直接基于AQS实现,通过内部类Sync来实现AQS同步功能。
CountDownLatch提供了两个方法:await、countDown。
CountDownLatch的作用:线程调用await等待资源(资源数不为0,进入阻塞),当前其它线程执行完代码调用countDown方法,资源数会减1(所以在初始化的时候要指定资源数),直到资源数位0,await的线程会被唤醒。
应用场景:一个线程等待其它所有线程都执行完,才开始执行。
代码结构
Sync静态内部类,继承了AQS,实现了同步方法
构造函数
需要传入起始资源数量
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
因为资源数大于0,可以推断CountDownLatch实现的是共享操作。
await
await调用AQS.acquireSharedInterruptibly(1)方法,acquireShared说明是共享操作。
Sync需要实现tryAcquireShared逻辑
public int tryAcquireShared(int acquires) {
return getState() == 0? 1 : -1;
}
非常简单,资源数不为0,就进入等待,返回 -1;
countDown
countDown调用AQS.releaseShared(1)方法,来看下tryReleaseShared实现
任何线程都可以调用countDown方法,所以Sync没有维护此有资源的线程引用,这里只有直接操作资源数就可以。
主要逻辑:
- 如果state == 0,直接返回 false,释放失败
- 通过CAS将state-1,返回true
小结:CountDownLatch代码超级简单,分析完后也可以发现,其state只能减,不能加,所以CountDownLatch是一次性同步工具,用完就没了。
Semaphore
Semaphore信号量也是直接基于AQS实现的,看代码结构,其内部也实现了公平锁和非公平锁。
Semaphore提供了几个方法:acquire和release
Semaphore的作用:设置一定共享资源数,允许指定数量的线程可以获取资源,其余线程等待,直到有资源被释放。
代码结构
- Sync 继承AQS,实现同步方法
- NonfairSync 非公平锁继承Sync
- FairSync 公平锁继承Sync
后面可以分析Semaphore与ReentrantLock的区别
构造函数
跟CountDownLath一样,需要指定共享资源数量,默认非公平锁实现
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
acquire
Semaphore不同之处在于,它居然可以acquire指定数量的资源,而不是默认1.
Semaphore是多资源的,所以与CountDownLath一样,也是实现了AQS的共享同步方法。
直接来看非公平锁的实现nonfairTryAcquireShared:
- 获取state,如果 state - acquires 可用资源数 < 0,返回进入等待;
- 如果 可用资源数 > 0,CAS更新state,成功返回 获取的资源数;更新失败,for自旋,重走步骤1。
release
tryReleaseShared:
- CAS更新state,成功返回true;失败,for自旋,直到更新成功,返回true
Executor
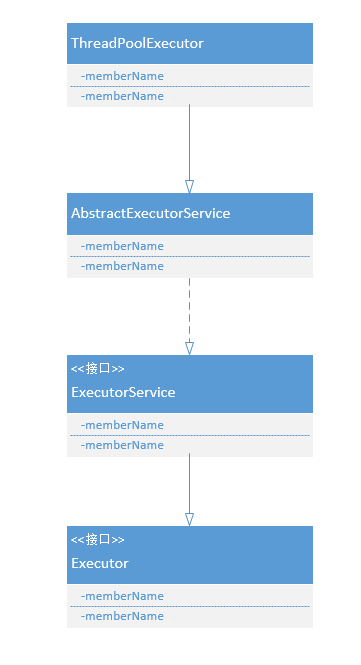
ThreadPoolExecutor
首先来看下其定义的5个内部类
- 任务的封装
- Worker 实现了Runnable接口,线程池中对任务的封装
- 四种拒绝策略
- CallerRunsPolicy 由调用线程执行
- AbortPolicy 抛异常
- DiscardPolicy 丢弃新任务
- DiscardOldestPolicy 丢弃最老的任务
小结:从ThreadPoolExecutor的类结构上可以清晰看出,内部类的一个大作用:代码可读性增强,结构清晰。
- 线程池的状态 volatile int runState
- RUNNING 0
- SHUTDOWN 1
- STOP 2
- TERMINATED 3
Wroker
四个成员变量
- ReentrantLock runLock 使用到了锁,执行run方法里使用到了锁
- Runnable firstTask 关联具体任务的,即用户提交的runnable任务
- long completedTasks 已完成任务的数量?
- Thread thread 当前执行任务的线程
构造函数
Worker的构造函数,将用户提交的Runnable任务赋值给firstTask变量。
run
主要的run方法,有两个步:
- runTask(task); 执行任务
- workerDone(this); 如果任务(包括队列里的任务)都执行完成,移除该线程
注意:这里有一个重大方法放在后面分析 – getTask()
runTask
这个方法用到了锁,来保证线程安全(为什么会不安全?一个任务会有多个线程执行?)。
从方法结构上来看,runTask方法就是给方法增加了before和after处理,有点像代理模式。
// 1. 调用before方法
beforeExecute(thread, task);
// 2. 执行任务
task.run();
// 3. 调用after方法
afterExecute(task, null);
目前的before和after方法都是空的,应该是给子类扩展用的。所以只有run方法。
小结:runTask方法没什么特别的地方,就是对run方法加锁,然后开始执行任务,最后记录已完成任务数量completedTasks+1。
workDone
workDone是外部类ThreadPoolExecutor提供的方法(这里的调用模式和FutureTask.Sync很像,也是任务执行完成后回调外部类的done方法)
workDone也是加锁(线程池有几把锁?)
Worker内部类的run方法使用的是Wroker的runLock锁,外部类workDone方法使用的是线程池的mainLock锁。
Worker.completedTasks记录Worker内任务完成数量,ThreadPoolExecutor.comletedTaskCount记录所有Wroker的completedTasks。
workDone方法的主要工作:
// 1. 将这个执行完任务的Worker从workers中移除
workers.remove(w);
// 2.
Worker内部类总结:runnable任务的封装,使用加锁方式确保任务被正确执行,任务执行完后从workers中移除。
目前遗留的几个问题:
- workers是什么?
现在继续往下看ThreadPoolExecutor提供的成员变量还有哪些
- 主要核心变量
- BlockingQueue
workQueue // 工作队列,用于存放堆积的任务。即阻塞队列,用户创建时传入的。 - ReentrantLock mainLock 锁,上面workDone方法用到了
- Condition termination = mainLock.newCondition() mainLock的条件变量
- HashSet
workers 表示线程池中的工作线程
- BlockingQueue
- 几个与线程池线程数量的重要参数
- volatile int poolSize 线程池当前线程的数量
- volatile int corePoolSize 线程池核心线程数
- volatile int maximumPoolSize 线程池最大线程数量
再来看下线程池的构造函数
构造函数只是做参数赋值,并没有特殊的操作。
那现在来看下任务的提交入口,线程池提供两种提交方式,execute和submit。submit最终也是调用execute方法,所以这里先只分析execute方法。
submit方法是在抽象父类AbstractExecutorService实现的,提供了三个重载实现,分别支持Runnable/Runnale T/Callable三种类型任务。最终都封装成FutureTask提到到线程池中。
execute(Runnable)
核心逻辑:
if poolSize < corePoolSize,addIfUnderCorePoolSize(command),如果当前线程数小于核心线程数量,创建新线程执行任务- 否则,即将任务入队
workQueue.offer(command) - 如果队列满了,且当前线程数小于最大线程数量,则创建新的额外线程处理该任务
addIfUnderMaximumPoolSize(这样的话,不是在队列里的任务就吃亏了?被插队?这里有玄机,还没有说外一层for循环的作用,看后面分析。) - 如果当前线程数也超过了最大线程数量,则拒绝任务
reject(command)
addIfUnderCorePoolSize
创建新的核心线程执行任务
- mainLock加锁来创建新的核心线程
- addThread创建新线程t
- 释放锁
- t.start()线程开始执行
addThread
主要工作就是创建一条新的线程,现在来看下内部细节:
- 创建一个Wroker,通过线程工厂创建一条新的线程,然后将任务和新的线程赋值给Worker。Worker是实际的执行者。
- 剩余动作,将新建的worker加入workers。所以workers保存的就是当前线程池的工作线程。然后poolSize++。
addIfUnderMaximumPoolSize
这里其实并不是去执行传入的新任务,而是从队列里取任务执行,返回执行的任务。
现在来看下这个方法的主要逻辑:
- 一样,mainLock加锁
- 从工作队列里取出第一个任务 next = workQueue.poll
- 创建新的额外线程 t 执行这个任务 next
- 释放锁
- 启动线程 t.start();
- 最后返回任务 next
那作为参数传入的task跑哪里去了?
if(next == null) {
next = firstTask;
}
看,只有当工作队列里没有任务,才会执行该新任务。所以线程池这里的实现还是很公平的,如果队列满了,新的线程会从队列里取任务执行,而不是直接执行后面这个新的任务。
那新任务如何处理?现在再来看execute方法的for循环
execute.for
主要接着上面情况继续分析。如果工作队列满了,这时候 addIfUnderMaximumPoolSize 返回的是队列里的第一个任务。那新任务就只能继续for循环再走一遍流程,期待工作队列能有位置空余出来。
那什么时候出发reject方法?
if(r == null) {
reject(command);
return;
}
那 r 什么时候为nul?
再回到 addIfUnderMaximumPoolSize 方法里
if (poolSize >= maximumPoolSize) {
return null;
}
所以如果当前线程数量达到了最大线程数量,则直接返回null。这时候execute方法就会执行拒绝策略了。
reject
现在最后来看看这个拒绝策略是怎么执行的。默认的拒绝策略是哪个?这里看下构造函数,用的是默认的成员变量
- RejectedExectionHandler defaultHandler = new AbortPolicy();
答案是AbortPolicy直接抛出异常,所以默认线程池如果满了,会直接跑异常。
reject方法很简单,就是调用RejectedExecutionHandler.rejectedExecution方法。
- AbortPolicy的实现是直接抛出异常
throw new RejectedExecutionException(); - CallerRunsPolicy简单粗暴,直接调用线程的run方法,不创建线程
- DiscardPolicy更简单,直接不处理,方法体为空,任务会消失
- DiscardOldestPolicy 先从workQueue里poll一个任务处理丢弃,然后再重新调用execute方法,尝试执行新任务
休息一小节,到目前为止,线程池的核心方法算是分析完成了,从构造函数到execute方法。
来一个小总结:线程池的实现,其实内部就是通过一个hashset维护了当前所有的工作线程,workQueue维护任务,同时通过参数控制线程数量。
那还有一些问题还没解释清楚:
- worker执行完,线程是如何处理的?
再来看workerDone
现在再来看一遍workerDone方法,当worker线程执行完任务后,会调用workerDone方法。前面分析了workerDone方法主要逻辑是将worker线程从workers移除。
所以现在停下来思考一下,线程池有corePoolSize和maximumPoolSize。只有在execute新增的时候会进行参数梳理的判断,任务执行完后就执行移除这个线程。– 等等,到这里是不是感觉那里出问题?线程池技术就是为了避免线程的创建和回收。那目前看的是并没有回收线程,而是直接remove掉。
getTask
答案在这里。getTask方法是由Worker.run方法调用的,现在再回过头来看看run方法的实现。
while(task != null || (task = getTask()) != null) {
runTask(task);
task = null;
}
Worker线程的run方法是一个while循环,只要工作队列里面有任务就会一直执行,如果任务都执行完了,就会清除该Worker线程。
比如一个任务提交后,创建了一个新的Worker来执行该任务,任务执行完成。如果不再提交新的任务,这个Worker就会被清除。
所以到目前为止再来总结一下线程池执行逻辑:
- 新任务提交,创建一个Worker执行任务
现在来分析下getTask方法的执行逻辑,先看看 RUNNING 语句块:
- 如果poolSize小于等于corePoolSize,直接workQueue.take(),返回新任务。这里调用的是take方法,所以会阻塞,直到有新的任务入队。
- 如果poolSize大于corePoolSize,说明当前工作的线程数量超过了核心线程数,那就意味着线程池中的线程多了。此处Worker会根据参数设置的线程存活时间keepAliveTime,尝试从workerQueue.poll(timeout)获取任务,如果在这个内获取到了新任务就返回继续执行;如果没有任务,则说明现在线程池工作没有那么紧张,可以回收当前Worker了,直接返回null。Worker.run方法将会执行workerDone(this)方法将自己移除。
所以其实线程池并不能保证最开始创建的那些线程可以一直执行,是根据数量来控制的,所以即使你是最早一批的线程,如果刚好在那个时间点你没有任务执行了,你就会被清除掉。
poolSize小于corePoolSize时,已创建的Worker线程会一直阻塞等待任务。超过corePoolSize时,就会根据存活时间将自己清除。
到这里总算是水落石出了,任务提交,新线程创建,线程清除都弄明白了。
上面所有分析的都是正常执行流程,ThreadPoolExecutor还提供了一些其它控制线程池的方法,我们来分析几个。
shutdown
shutdown()方法,关闭线程池,先来看下这个方法的代码主逻辑:
- mainLock加锁
- runState = SHUTDOWN 将线程池运行状态更改为shutdown,此时停止接收新的任务;execute方法对新任务会调用reject方法,Worker.run会继续执行,将已提交的任务执行完成。继续从workQueue取任务,直到workQueue空。
- 调用每个Worker的interruptIfIdel(),看名字是当Worker空闲也就是没在执行任务的时候,设置Worker线程的“中断”标志位,告诉你要中断了。该方法会tryLock尝试获取锁,判断当前线程是否在执行任务。如果在执行任务获取锁失败,否者更新“中断”标记。
- 结束,没再做其它事情了
小结:shutdown方法,就做了两件事情:
- 将线程池状态改为 SHUTDOWN;停止接收新的任务
- 给所有Worker线程发出“中断”信号。等到所有已提交的任务都执行完成
那现在再来看下Worker什么时候会响应这个中断?
再看Worker.run的interrupt
Worker.run方法有catch InterruptedException异常,所以说这里可能会响应中断。
这里补充下知识点,线程处于阻塞状态才会响应中断,否者会继续执行。
run代码块总共调用了两个方法:runTask和getTask。
runTask方法先加锁然后调用了Thread.interrupted()方法(interrupted方法,会重置中断标识位),所以runTask不会响应中断,会保证任务的执行。
getTask方法,那阻塞的地方就多了:
- RUNNING 语句块的 workQueue.take() 阻塞等待任务 以及 workQueue.poll(timeout) 定时等待。shutdown的时候会这两个方法都会退出等待,并抛出interruptted异常;
所以Worker什么时候会响应shutdown方法的中断?
答案就是当阻塞等待任务的时候。
所以shutdown方法会等所有已提交任务都执行完,线程池才退出。
shutdownNow
那shutdownNow呢?看这个Now就可以看出,肯定是直接关闭,抛弃剩余的任务。现在来看看是不是这样的。
shutdownNow代码主体逻辑:
- mainLock加锁
- 将线程池状态更改为 STOP (这里还有一个TERMINATED状态),此时停止接收新的任务;execute方法对新提交的任务会执行reject方法,Worker.run也会对还未执行的任务停止执行(其中runTask方法会直接return,getTask方法也会return null,这样Worker会执行清除)。
- 调用每个Worker的interruptNow()方法,标记每个Worker线程的“中断”标记位。不管当前线程有没在执行任务,直接标记。
小结:shutdownNow方法,也是做几件事情:
- 停止接收新的任务;
- 中断当前正在执行的任务;
- 忽略已提交的任务,即工作队列里的任务
awaitTermination
居然还要一个这个方法
remove
terminated
泛型
使用多态进行对象类型转换,只能在运行时发现异常并抛出异常。泛型能够在编译器就检测出异常。
什么是泛型?作用是什么?泛型的使用?优缺点?实现原理?应用场景?
什么是泛型?
将类型的推断工作推迟到对象创建的时候。
泛型的使用
- 通配符
?,表示可以存放任意对象类型 - 限制符:extends/super,
? extends Parent只能存放Parent及其子类;? super Child只能存放Child及其父类 - 通用符
T,任意大写字母,表示只能存放T对象类型,T可以是任何对象类型在类申明后面申明通用符
T,则类的变量、方法(参数、返回值)都可以使用该T类型
应用场景
集合类大量应用泛型技术,集合内部将数据全部当做Object来处理,对装入的对象没有任何限制,更加灵活。但是取出的时候需要做强制类型转换,所以为了防止ClassCastException,代码上需要做好判断。
当然也可以给集合类指定对象类型,这样就限制了存放的类型,取出时也不需要进行类库转换。
ArrayList<E>E只能是引用类型
实现原理/优缺点/作用是什么
在编译阶段,编译器只是将泛型类全部转为了Object类型(擦除),所以泛型并没有提高任何性能,只是简化了代码的编写。
Java的泛型只是编译器的泛型,一旦编译成字节码,泛型就被擦除了。
装箱/拆箱
基本类型和引用类型的自动转换。
基本数据类型不需要使用new来创建,它们不会在堆上创建,而是直接在栈内存储,比对象更高效。
为什么需要这个功能
装箱/拆箱的实现原理
反编译后的代码,可以看出,比如Integer类
- 装箱:调用的是Integer包装类的valueOf()方法实现的,new一个新的Integer实例
- 拆箱:调用的是Integer包装类的intValue()方法实现的,返回Integer实例的值
自动装箱场景
- 基本数据类型放入集合类中的时候,会进行自动装箱。
- 基本数据类型和包装类型进行比较/运算,会将包装类进行拆箱成基本数据类型,然后再进行。
Integer的缓存机制
先来看一下下面这段代码:
public static void main(String[] args) {
Integer a = 1;
Integer b = 1;
Integer c = 128;
Integer d = 128;
System.out.println(a == b); // 竟然:输出 true,利用缓存,返回的是同一个对象
System.out.println(c == d); // 常理:输出 false,超出cache范围,返回的是新创建的对象
}四个变量的赋值都发生了自动装箱操作,Integer的自动装箱调用的是valueOf方法,valueOf方法内部维护了一个Integer cache[]缓存数组。如果是-128~127之间的数字会自动缓存到cache中,超出范围的就new Integer新对象处理。
cache的范围是可以配置的。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}Byte、Short、Long、Character也有相同的缓存机制,值得注意的是Double、Float是没有缓存机制的。
自动装箱缺点
- 自动装箱会创建对象,频繁的装箱操作会消耗内存,影响性能,所以可以避免装箱就应该避免。
- 有些场景会自动拆箱,需要注意包装类的对象是否为null,否则拆箱时会报空指针异常。
- 包装对象的比较不能用
==,要使用equals比较。
AQS
AQS提供对资源的独占和共享操作。
独占方式一般实现的操作有:
- tryAcquire
- tryRelease
- isHeldExclusively
共享方式一般实现的操作有:
- tryAcquireShared
- tryReleaseShared
Node
我们来看下AQS这个等待队列是如何设计的?
Node 是AQS的静态内部类
1.三个状态 volatile int waitStatus
- CANCELLED 1 表示当前thread已被取消
- SIGNAL -1 表示当前thread可以被唤醒 unpark 方法
- CONDITION -2 表示当前thread正在等待条件 signal 唤醒
2.三个重要变量
- volatile Node prev 说明Node队列是一个双向链表
- volatile Node next
- volatile Thread thread 说明每个Node还保存了当前挂起的线程thread
在外部类AQS里定义了两个成员变量:
- volatile Node head
- volatile Node tail
3.等待队列中的下一个节点
- Node nextWaiter 用于等待队列,执行下一个节点
4.构造函数
这里的构造函数设计有的奇妙,提供了三个构造函数,接收的参数不一样
第一个是无参构造函数,就是直接创建一个Node节点
第二个是接收thread和node两个参数,node表示节点的类型是共享还是独占。这里使用的是nextWaiter来指向传入的这个Node。(为什么不直接定义一个叫nodeType的变量呢?)
第三个是接收thread和waitStatus两个参数,设置当前节点的等待状态
- 再来补充两个静态成员变量
- static final Node SHARED = new Node() 表示节点是共享模式
- static final Node EXCLUSIVE = null 表示节点是独占模式
这两个节点用来表示Node节点的类型,SHARED表示共享类型节点,EXCLUSIVE表示独占类型节点。通过构造函数传入Node类型。独占类型的节点说明是在获取独占锁资源失败创建的节点,共享类型的节点说明是在获取共享锁资源失败创建的节点。
- 两个实例方法
- boolean isShared() 判断 nextWaiter == SHARED ?
- Node predecessor() 返回上一个节点 prev;
这里先来一个小结: 目前通过只分析Node类发现,Node是一个双向链表,保存了当前等待的线程。由Node构建的这个队列叫做同步队列。acquire获取资源失败,线程就会加入到这个队列中。
AQS.addWaiter
上面分析完了Node节点,现在我们来看看addWaiter是如何将Node入队的。
首先我们已知AQS有acquire和acquireShare两种获取资源实现方式。acquire 独占,acquireShare 共享,所以这两个方法创建的Node节点也是有区别。acquire 创建的是 Node.EXCLUSIVE 独占类型的节点,acquireShare 创建的是 Node.SHARED 共享类型的节点。
addWaiter方法主要逻辑:
- 创建一个独占类型的Node
Node node = new Node(Thread.currentThread(), mode); - 通过CAS方式将Node加入尾 tail
ConditionObject
成员变量
- Node firstWaiter
- Node lastWaiter
Future
Future接口提供了对任务的生命周期管理,定义了cancel任务取消、isDone任务是否完成、get阻塞获取任务结果等方法。
FutureTask
实现了Future和Runnable接口,内部持有一个sync锁,基于AQS实现。
带着问题来学习:
- FutureTask的实现原理?
- AQS锁应用在哪里?作用是什么?
内部类Sync使用了AQS锁,是一个非静态的内部类,因为要调用外部类的done方法。所以说任务执行完成,应该是由sync来通知的。
sync是公平还是非公平?
构造函数
FutureTask提供两个构造函数,一个接收Callable型任务,一个接收Runnable、result回调接口。这两个构造函数内部到创建了一个sync实例。
# Callable构造函数内部
sync = new Sync(callable);
# Runnable、result构造函数内部
sync = new Sync(Executors.callable(runnable, result));
从这里可以看出FutureTask内部是通过Sync实现的。
run
在分析Sync类之前先看下run方法。
sync.innerRun();
run方法只有一行代码,就是调用sync的innerRun方法,所以FutureTask其实将任务的执行都委托个sync来实现了。
Sync
Sync定义了三个状态
- RUNNING 1 任务正在运行
- RAN 2 任务已完成
- CANCELLED 4 任务已取消
Sync定义了四个成员变量
- Callable
callalbe 任务 - V result 回调函数
- Throwable exception 任务可能抛出的异常
- volatile Thread runner 当前执行任务的线程,volatile修饰,从目前进度来看,FutureTask是存放多线程并发场景?
目前有两类线程会访问这个类,第一个是执行任务的是线程池里的线程,第二个是用户线程会调用get方法获取结果,但目前还未看出有竞争可能。
Sync会记录执行当前任务的线程,是哪个线程正在执行。
看了下Sync的实现方法,它是一把共享锁。
Sync.innerRun()方法,真正执行任务的入口
从这个方法开始,发现Sync内部每个方法都使用CAS进行无锁更新操作。所以FutureTask的实现时基于AQS和CAS设计的。
# 1. 更新任务状态为RUNNING
compareAndSetState(0, RUNNING);
# 2. 记录当前执行任务的线程
runner = Thread.currentThread();
# 这行代码有两个步骤:
# 第一步:调用callable.call()方法开始执行任务(这里阻塞),任务执行完后,执行步骤二
# 第二步:将任务结果传入innserSet方法,目前可以理解这个innertSet方法只是将任务状态更新为已完成
innerSet(callable.call());
# 接下来看下这个innerSet方法的作用
小结:innerRun方法调用callable.call方法开始执行任务
注意:compareAndSetState(0, RUNNING);,这里将任务状态保存到AQS的state变量中,FutureTask并没有用state做资源控制,而是自己重写了控制方法。
Sync.innerSet方法,更新任务状态为已完成
通过自旋方式将任务状态更新为已完成,然后调用外部类的done方法,通知任务执行完成。
小结:截止到这里的分析来看,使用AQS和CAS,也许是为了防止任务被多次执行。从innerRun方法就有迹象,通过CAS来更新任务状态,防止多次执行。
问题来了,FutureTask什么情况下会被多个线程执行到?
上面把任务执行run方法流程给分析完了,现在来看下get方法的实现逻辑
FutureTask.get
代码也只有一行,实际调用的是sync的innerGet方法
sync.innerGet();
在分析这个代码前,要有AQS的基础知识,要不然看起来费劲。
sync.innerGet
Sync实现的是共享锁,get操作就是去尝试获取资源,实现tryAcquireShared方法。现在来看下FutureTask.Sync是如何实现这个方法的。
# Sync.tryAcquireShared方法内部调用innerIsDone方法判断任务是否执行完成。
# 如果任务已结束,返回 1;否则返回 -1。
return innerIsDone() ? 1 : -1;
小结:get方法通过判断当前任务状态来执行,如果当前任务未结束,则进入AQS的等待队列,挂起当前用户线程。有挂起那就有唤醒,所以来继续把上面没讲的内容来完善一下,看是如何唤醒的。
void innerSet(V v) {
// 1. 自旋方式,将任务状态更新为已完成
for (; ; ) {
// 获取任务执行状态
int s = getState();
// 如果任务已结束或者已取消,直接返回
if (ranOrCancelled(s))
return;
// 将任务更新为已完成
if (compareAndSetState(s, RAN))
break;
}
result = v;
// 3. 释放资源,唤醒在等待队列的用户线程,通知其任务已执行完成
releaseShared(0);
// 2. 调用外部类的done方法
done();
}
任务执行完后,会releaseShared释放资源,这是等待队列的线程就被唤醒。
总结:FutureTask是通过AQS锁来实现线程等待的,get操作就是去获取资源。如果任务未完成,get操作获取资源失败就会进入AQS的等待队列阻塞等待资源。任务执行完成时,会释放资源,并唤醒在等待队列的线程。get操作将成功返回。
注意:FutureTask的AQS.state被用来保存任务的状态,并不是来做共享资源控制的。
问题一:get方法可以调用多次吗?即任务直接完成后,多次调用get会怎么样?
- FutureTask.Sync实现的是共享锁,所以get方法可以被调用多次。任务执行完成后,每次调用get都会返回任务执行结果。
- 上面这句话解释的不是很准确,看了源码实现,FutureTask.Sync其实并没有对state资源数做控制,重写了获取资源方法,只要任务已结束,就都返回 1,即获取资源成功。但是并没有真的去更新AQS的state值。
AQS正常实现逻辑是acquire成功state+1,release成功state-1,当state==0时,acquire才能成功否则进入等待。
TODO:未完待续
- tryAcquireShared
- tryReleaseShared
- 同时分析下ReentrantLock这两个方法的实现
CompletionService
接口作用:让异步任务的结果有序化
实现类:ExecutorCompletionService 内部通过一个队列(BlockingQueue)帮我们把结果存储起来了,而且是按顺序存储,我们只有遍历这个队列就可以获取到任务的执行结果。
但是要注意,这个队列默认是用LinkedBlockingQueue,如果一直没有去消费这个队列,会造成内存溢出。
实现原理:任务封装成FutureTask,利用了FutureTask的done方法,重写了该方法,当任务执行完后,加入队列。
ExecutorCompletionService
两个成员变量
- Executor executor; // 执行任务的线程池
- BlockingQueue<Future
> completionQueue; // 任务完成队列,可以从这个队列按FIFO顺序获取执行结果
构造函数也就是接收这个两个参数,默认使用LinkedBlockingQueue存放已完成任务执行结果。
submit 方法就是将任务提交到executor线程池去实现。
这里将提交的任务做了一个封装
QueueingFuture f = new QueueingFuture(task);
QueueingFuture内部类,继承FutureTask,重点在这里,重写了FutureTask的done方法。
completionQueue.add(this);
任务执行完成后,将任务添加到队列中。
take/poll 方法就是从队列取数据,任务出队
总结:CompletionService的实现,其实就是利用了FutureTask的done方法,和一个同步队列存放执行结果。
额外问题:done方法是谁调用的?
就是FutureTask.Sync方法,在任务执行完后会调用FutureTask.done方法,所以在这里将任务添加到了队列中。
枚举
java.lang.Enum 枚举类,JDK 1.5 引入了枚举类型,这是一个泛型抽象类,但是编译器不允许我们在代码里直接继承它。我们自定义的enum枚举类,代码编译后,编译器会为该枚举类自动继承java.lang.Enum类并将类声明为final类型(所处enum枚举类是不可以继承的),同时枚举类里的每个枚举值在类初始化阶段都会实例化为我们定义的枚举类对象。同时类中还新增了values和valueOf方法。