redis.conf配置文件
redis.conf常见参数,以下是基于Redis5的配置说明
./redis-server /path/to/redis.conf 按照指定的配置文件启动 include /path/to/other.conf 包含其它的redis配置文件
NETWORK
网络配置
- bind 127.0.0.1
- protected-mode yes 默认开启安全模式,必须要bind ip或则设计了password才能访问
- port 6379 默认6379,如果设置为0会怎么样?
- tcp-backlog 511 表示tcp连接中已完成3次握手的队列长度,tcp连接中有两个队列,一个等待队列,一个完成队列。系统并发连接量大时,可以调大该值,避免客户端连接缓慢。注意,该值应小于Linux系统的/proc/sys/net/core/somaxconn的值(默认128)。
- timeout 0 客户端心跳超时时间,超时后断开连接,0表示不启用
- tcp-keepalive 300 心跳检测包,定时向client发送tcp_ack包探测client是否存活
GENERAL
基本配置
- daemonize no 是否以守护进程方式启动
- supervised no 系统启动方式
- loglevel notice 日志等级
- databases 16 设置数据库数量,启动时创建16个数据库,默认选择第0个数据库DB0,使用
select <dbid>可以切换数据库。数据库间的数据是相互隔离的,客户端可以选择不同的数据库。
SNAPSHOTTING
RDB快照方式,Redis的默认持久化方式。
适合小规模数据或丢失一部分数据也不会造成问题的应用
持久化频率
- save 900 1
- save 300 10
- save 60 10000 指定在多长时间内,多少次更新操作,就将数据同步到数据库文件。 例如60秒内有10000次修改操作,就将数据同步到数据库。
- stop-writes-on-bgsave-error yes yes Redis 会创建一个新的后台进程dump_rdb,同步数据。但是如果后台进程出现问题,主进程也会拒绝写入。 如果设置为no,即bgsave进程报错,也不影响主进程运行。
- rdbcompression yes 启用压缩,对字符串进行压缩
- rdbchecksum yes 启用CRC64校验码
SECURITY
- requirepass foobared 客户端连接需要密码认证
CLIENTS
- maxclients 10000 客户端最大连接数
MEMORY MANAGEMENT
当内存达到上限时,Redis可以配置六种方来释放内存
volatile-lfu -> Evict using approximated LFU among the keys with an expire set. allkeys-lfu -> Evict any key using approximated LFU. volatile-random -> Remove a random key among the ones with an expire set. allkeys-random -> Remove a random key, any key. volatile-ttl -> Remove the key with the nearest expire time (minor TTL) noeviction -> Don’t evict anything, just return an error on write operations.
- maxmemory-policy noeviction 默认不释放内存,直接返回错误
REPLICATION
主从相关的配置
Redis的主从复制采用异步方式进行。
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
- replica-serve-stale-data yes Redis Master主节点可以继续接受客户端的请求
- replica-read-only yes Redis Replica从节点只读
- repl-diskless-sync no Redis支持两种拷贝策略:文件或Socket;文件方式:master将数据写入磁盘文件,然后replica读取该文件。socket方式:master将数据直接通过socket发送给replica。
基于socket方法,master一次只能与一个replica进行数据备份,其他replica只能等待。
- repl-diskless-sync-delay 5
- repl-disable-tcp-nodelay no 是否启用TCP_NODELAY,no master数据会立即传输到replica。
- replica-priority 100 优先级,sentinel选择新master的依据,当master下线,从replica中选择优先级最大的作为新master。
LAZY FREEING
Redis有两种方式来删除key
- DEL 阻塞方式:使用DEL,Redis将会停止接收客户端的请求,开始对过期的key进行删除。
- UNLINK 非阻塞方式:Redis使用另一个线程来删除key,不会阻塞主线程。
- lazyfree-lazy-eviction no 使用DEL同步方式释放内存
- lazyfree-lazy-expire no 使用DEL同步方式删除过期key
- lazyfree-lazy-server-del no
- replica-lazy-flush no
APPEND ONLY MODE
数据持久化相关配置
Redis默认采用异步方式持久化数据文件的。
Redis支持AOF和RDB两种持久化方法,两种方式可以同时使用。
AOF模式的配置参数
- appendonly no 是否启用AOF模式,no 默认不启用
- appendfsync everysec AOF持久化频率,有3种选项:always 有新数据写入就刷盘;everysec 每秒刷一次;no 使用操作系统自身的刷盘策略
- no-appendfsync-on-rewrite no 在AOF重写期间,是否允许执行AOF文件同步。 no 允许,在AOF重写期间,允许AOF文件继续执行写入,新的命令会写入AOF文件;yes 不允许 将会阻塞AOF文件写入,命令暂存在aof缓存中。对于延迟要求高的应用,可以设置为yes。
no 重写期间,AOF文件也可以执行写入,这样会存在文件句柄的竞争,造成时延。但安全性高,新的命令会写入AOF文件,即使宕机也可以全部恢复。 yes 重写期间,会阻塞appendfsync方法执行,即阻塞AOF缓存写入文件和同步,新命令全部暂存在aof_buf缓存区,由操作系统策略执行写文件(Linux默认30s)。所以如果意外宕机,这期间的数据会丢失。
- auto-aof-rewrite-percentage 100 AOF文件大小与上一次的大小比率超过100%,触发重写
- auto-aof-rewrite-min-size 64mb AOF文件超过64M,触发重写
- aof-load-truncated yes
- aof-use-rdb-preamble yes
REDIS CLUSTER
Redis集群相关的配置
Redis单个实例必须要以cluster集群身份启动才能作为集群节点。
- cluster-enabled yes 作为集群节点启动
- cluster-config-file nodes-6379.conf 集群节点配置文件,由Redis自动创建和维护
- cluster-node-timeout 15000 集群节点超时时间
sentinel.conf配置文件
- sentinel down-after-milliseconds mymaster 30000 sentinel监控master,如果master在30s内未有回复,sentinel将认为master已下线。
注意:不同sentinel的down-after-milliseconds时长可能不同,所以判断时间不一样。
- sentinel monitor mymaster 127.0.0.1 6379 2 监控master
sentinel monitor
quorum 表示sentinel判断其下线的数量
常用命令
set
get
select
del
hset
add
push
slaveof
设置key的过期时间
expire/pexpire
setex
键过期策略
支持三种键过期处理策略
- 定时
- 惰性
- 定期
Redis使用惰性和定期两种策略
在持久化AOF和RDB中,和主从复制中这两者是如何处理过期的键?
RDB
持久化:过期的键不持久化到RDB文件中 载入:
AOF:
持久化:过期的键Master会写入DEL删除命令 载入:检查键是否过期
复制:
同步:Master发送DEL命令,Replica执行删除过期键
内存淘汰策略
提供六种内存键淘汰策略
- 默认不淘汰
- 所有键中,LRU最近最少使用淘汰
- 所有键中,Radom随机淘汰
- 被设置了过期的键中,LRU最近最少使用淘汰
- 被设置了过期的键中,Radom随机淘汰
- 被设置了过期的键中,TTL存活时间最短的淘汰
持久化策略
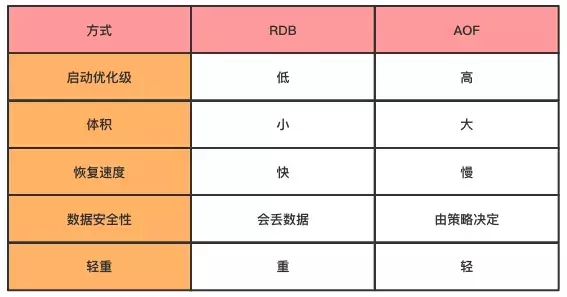
Redis提供两种持久化方式:RDB和AOF。Redis允许两者结合一起使用。 RDB:可以定时备份内存中的数据集。服务器启动的时候,可以从RDB文件中恢复数据集。 AOF:记录服务器的所有写操作。服务器启动的时候,会把所有写操作重新执行一遍,从而实现数据备份。
默认使用RDB方式。
RDB
RDB可以手动执行,也可以根据配置文件选择定期执行。RDB方式生成的文件是一个经过压缩的二进制文件,通过该文件可以还原当时数据库的状态。
何时触发
可以手动或者自动触发
手动触发:执行SAVE或则BGSAVE命令。
自动触发:根据配置文件里的save参数条件,自动触发BGSAVE命令。
RDB文件生成
两个Redis命令生成RDB文件:
- SAVE 由当前进程执行,会阻塞Redis服务器进程,直到RDB文件创建完毕为止。阻塞期间,服务器不能处理任何命令请求。
- BGSAVE 由后台执行,会fork派生一个子进程,由子进程执行负责创建RDB文件,服务器进程继续处理命令请求。
实际创建RDB文件都是由rdb.c/rdbSave函数完成
rdb.c/rdbSave函数写文件,rdb.c/rdbLoad函数重载文件。持久化的文件是一份压缩的二进制文件。
RDB文件载入
RDB的载入工作,是在服务器启动的时候自动执行的,所以没有专门命令用于载入RDB文件。Redis启动时检测到RDB文件的存在,就会自动载入RDB文件。
因为AOF文件的更新频率高于RDB文件,所以服务器启动时会优先使用AOF文件来还原数据。只有在AOF持久化功能关闭的状态才会使用RDB文件来还原。
struct redisServer {
long long dirty; // 计数器,记录距离上次dump后,服务器对数据库状态的操作次数 64位(long 32位)
time_t lastsave; // 上次dump的时间
};serverCron 定时函数,定期执行任务。
RDB文件结构 REDIS|db_version|databases|EOF|check_sum
databases数据结构 SELECTDB|db_number|key_value_pairs
key_value_pairs数据结构 TYPE|key|value 不带过期时间的键值对 EXPIRETIME_MS|ms|TYPE|key|value 带过期时间的键值对
value数据结构 ENCODING|integer len|string list_length|item1|item2|…|itemN set_size|elem1|elem2|…|elemN hash_size|key_value_pair1|key_value_pair2|…|key_value_pairN -> key1|value1|key2|value2|…|keyN|valueN
保存频率
持久化频率条件:
- save 900 1,900秒内对数据库进行至少一次修改
- save 300 10
- save 60 10000
满足以上条件,Redis会自动执行SAVE或BASAVE命令。
Redis默认是阻塞同步,即SAVE命令模式执行。
优势和劣势
优势:
- 在恢复大数据集时的速度,RDB比AOF快;
劣势:
- RDB不是实时,可能存在部分数据丢失问题。
参考链接:https://www.cnblogs.com/ysocean/p/9114268.html
AOF
AOF(append only file)是记录了数据的变更,RDB是保存了数据本身。持久化的文件是一份文本文件。
AOF保存所有的写命令。 W rewriteAppendOnlyFile()函数写文件,loadAppendOnlyFile()函数重载文件。
struct redisServer {
sds aof_buf; // AOF缓冲区
};AOF文件生成
AOF持久化三步骤
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
- 命令追加(append):服务器执行完一条写命令后,会以协议格式将命令追加到aof_buf缓冲区的末尾。
- 文件的写入与同步:执行完写命令后,会调用flushAppendOnlyFile函数检查aof_buf缓冲区是否可以写入AOF文件。
appendfsync选项:
- always,每个事件循环都将aof_buf缓冲区写入AOF文件,并且同步AOF文件。效率最慢,安全最高。
- everysec,每个事件循环都将aof_buf缓冲区写入AOF文件,并且每隔一秒在子线程中对AOF文件进行一次同步。效率较高,丢失一秒数据。
- no,每个事件循环都将aof_buf缓冲区写入AOF文件,然后由操作系统决定什么时候同步文件。效率最快,丢失上一次同步数据。
AOF文件的载入与数据还原: 1)创建一个伪客户端(fake client); 2)从AOF文件分析并读取出一条写命令; 3)使用伪客户端执行写命令; 4)一直循环2,3步骤,知道AOF文件所有写命令被处理完毕; 5)载入完毕。
AOF文件载入
因为AOF文件里面包含了数据库的所有写命令,所以Redis只要重新执行一遍AOF文件里的所有命令即可将数据库还原。
Redis启动一个伪客户端,载入AOF文件,然后将命令发送服务端执行。
AOF文件过大问题
AOF重写
AOF持久化会记录所有的写命令,随着运行时间的流逝,AOF文件内存会越来越多大。为了解决AOF文件体积膨胀问题,Redis提供了AOF文件重写(rewrite)功能。通过创建一个新的AOF文件替代现有AOF文件,新旧两个AOF文件所保存数据库状态相同,但新AOF文件不包含冗余命令。
AOF重写实际就是只记录数据的最终状态。一条数据,中间往往会被修改多次,AOF不需要把每一条操作命令都记录执行,只要把最终的那条数据状态生成一条写命令即可。这样就可以节省非常多的命令和执行时间。 重写是采用新的子进程执行。
AOF重写的好处:
- 压缩AOF文件,减少磁盘占用量;
- 将AOF的命令压缩到最小集,加快数据恢复速度。
重写原理:并不是去一条条解析旧AOF文件的所有写命令,而是去比对当前数据库状态来实现的。首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这就是AOF重写功能的实现原理。
AOF重写不会对现有的AOF文件进行任何读取、分析操作,而是直接读取服务器当前状态实现的。
因为aof_rewrite函数生成的新AOF文件只包含还原当前数据库状态所必须的命令,所以新AOF文件不会浪费任何硬盘空间。
何时重写
当AOF文件大于64M(auto-aof-rewrite-min-size配置大小)触发重写
AOF重写可以手动触发和自动触发。
手动触发:执行BGREWRITEAOF命令。
自动触发:
Redis在AOF功能开启情况下,会维护三个变量:
- 当前AOF文件大小
aof_current_size - 上一次AOF重写后的文件大小
aof_rewrite_base_size - 增长百分比
aof_rewrite_perc
Redis会定期检查以下条件是否满足,如果全部满足就会自动触发重写:
- 没有RDB或AOF在执行
- 没有
BGREWRITEAOF重写在执行 - 当前AOF文件大小大于
auto-aof-rewrite-min-size(默认64mb) - 当前AOF文件大小和最后一次的大小之间比率大于
auto-aof-rewrite-percentage值
如何重写
因为重写需要耗费大量时间,所以Redis使用后台进程(子进程)来执行重写操作。
- 子进程重写期间,主进程可以继续处理命令请求;
- 使用子进程而不是线程,可以避免锁竞争,确保数据安全性。
AOF后台重写 BGREWRITEAOF命令 aof_rewrite函数会进行大量写入操作,线程将被长时间阻塞,所以Redis将AOF重写程序放到子进程里执行。
- 子进程重写期间,父进程可以继续处理命令请求。
- 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以避免使用锁的情况下,包装数据的安全性。
重写期间,新产生的数据如何处理?
一句话:重写也有缓冲区,Redis会将新的写命令同时也追加到AOF重写的缓冲区(之前是只追加到AOF缓冲区)。
子进程重写的问题:子进程重写期间,父进程还会继续执行命令请求,会造成状态不一致。所以在子进程重写期间,父进程同时要执行三个工作:
- 执行客户端发来的命令;
- 将执行后的命令追加到AOF缓冲区;
- 将执行后的命令追加到AOF重写缓冲区。
当子进程重写完成后,会向父进程发送一个信号,父进程调用信号处理函数。将AOF重写缓冲区中的内容写入新AOF文件中,这样新AOF文件的数据库状态就和当前一致了。最后再将新AOF文件改名覆盖掉现有AOF文件,完成新旧AOF文件的替换。这种方式只有在信号处理函数执行时才会对父进程造成阻塞。
AOF重写相关配置
no-appendfsync-on-rewrite 重写期间不允许执行AOF文件写入
默认no,就是允许。
参数说明:AOF重写会占用IO,如果文件过大,耗时会很长,其他IO操作(如AOF文件写入操作)会被阻塞,等待时间长。所以为了防止AOF重写期间一直占用IO,no-appendfsync-on-rewrite参数设置为no,允许AOF文件写入执行。允许AOF文件同时写入,能够确保新的命令及时刷盘。如果阻塞AOF的文件写入,在这期间的新命令都会暂存在aof_buf缓存中,由操作系统策略执行文件写入(Linux默认30s刷盘)。如果在这30s内,Redis发生宕机,则aof_buf中的数据会丢失。
文件格式
以Redis命令请求格式保存。
主从策略
如何复制
Redis可以使用slaveof命令,让一台服务器(replica)去复制(replicate)另一台服务器(master)。
怎么复制
第一次进行同步,执行slaveof命令:发送RDB文件
- replica客户端发送
sync命令到master服务端; - master执行
bgsave命令生成RDB文件,然后将RDB文件发给replica客户端; - replica加载RDB文件,恢复文件数据;
- master将
bgsave期间新接收的写命令也发送给replica客户端,确保数据最终一致。
同步完成后,之后命令传播:发送操作命令
- master接收到新的写命令时,同时发给replica客户端,确保master和replica数据一致。
这一版本存在的问题:
replica断线重连后要重新执行
sync命令。
如果命令传播过程中,replica断线重连,那replica会重新发送salveof命令,master再次生成RDB文件,发给replica,replica重新载入RDB文件。
replica每次断线重连,都需要重新只看一遍sync命令,这种方式效率低。
新版本的优化:
使用psync替换sync命令。
psync提供完全重同步和部分重同步功能。
- 完全重同步:类似
sync命令操作,replica断线重连后重新执行一遍同步操作。 - 部分重同步:replica断线重连后只处理断线后的复制。
psync如何实现的
复制偏移量
psync的部分重同步功能主要是通过记录复制偏移量实现的。
master的复制偏移量,记录了发送给replica的字节数
replica的复制偏移量,记录了接收到的字节数
通过对比master和replica的复制偏移量可以轻松判断和实现主从的数据一致性。
复制积压缓存区
master每次将写命令发送给replica时,同时也会发个复制积压缓冲区队列(默认1M)。
如果replica断线重连,会将自己的复制偏移量发给master,master比对偏移量位置。从缓冲区队列取出偏差数据,发送给replica。
如果缓冲区队列中没有该偏移量之后的数据,master则会执行全部重同步操作。
自动复制
相关配置参数
主/从切换 哨兵模式(Sentienl)
如何部署
需要部署至少3个哨兵实例,一主二从三哨兵。
redis.conf配置主从,sentinel.conf配置哨兵。master和哨兵分机器部署。
sentinel.conf都需监控master节点 monitor master ip port num
分别启动主从,再启动哨兵。
# 启动sentinel
./redis-sentinel /path/to/your/sentinel.conf
sentinel启动过程
- sentinel本质也是一个Redis服务器,所以启动就是初始化一个普通的Redis服务器,只是工作的内容不同。
- 初始化成功后,sentinel创建与master服务器的连接。
这里会创建两个连接:
- 命令连接,与master服务器收发命令;
- 订阅连接,订阅master服务器的_sentinel_:hello频道?这是什么作用?
- sentinel通过命令连接通道,发送INFO命令,获取master信息和slave信息。
- sentinel创建与slave服务器的连接,并发送INFO命令。
如何判断master是否下线
sentinel会与master保持连接,master超过down-after-milliseconds时长未恢复,sentinel则认为其可能下线。然后sentinel会向同样监视这一master的sentinel询问是否也认为其下线(is-master-down-by-addr命令)。如果认定其下线的数量足够,sentinel则会执行故障转移切换。
如何切换
当sentinel已判定master下线,将会与各个sentinel协商选举一个领头sentinel。
- 选举领头sentinel
- 由领头sentinel执行故障转移
故障转移
- 从已下线master的replica中,挑选一个服务器转为master
- 让其他replica改为复制新的master
sentinel向replica发送
slaveof命令 - 将下线的master设置为replica
新master如何挑选
根据replica的优先级进行选择
如果优先级相同,则选择复制偏移量最大的replica 如果复制偏移量也相同,选择运行ID最小的。
选择依据:优先级 > 复制偏移量 > 运行ID。
客户端如何识别新master?
集群
集群概念
集群通过分片(sharding)实现数据共享,并提供复制(replicate)和故障转移(failover)功能。
集群实现node
集群由多个节点(node)组成,redis服务必须以节点方式启动(配置参数cluster-enabled yes)。节点之间互相通信,去中心化的,不存在中心节点或代理节点。
sharding
replicate
failover
一致性哈希
为什么会有一致性哈希?
通常的哈希算法,是基于固定数量的哈希计算,是基于相同数量的取值。如果数量改变了,每个元素的哈希值也会变动。在集群环境下,机器数量是会动态变化的,如果会普通的哈希算法来划分,一旦数量有变化会导致所有节点都失效要重新计算分配。特别是在缓存场景,如果机器数量一变动的话,所有缓存都会立即失效。
那什么是一致性哈希?
一致性哈希算法是能够确保当机器数量有变动时,只会影响到对应机器和相邻机器间的数据,不会影响到其它机器。所以一致性哈希能够避免所有数据集体失效。
那是如何实现的?设计原理?
传统的哈希算法是基于机器数量进行取模,一致性哈希是基于2^32次方取模。将这个哈希值空间组织成一个虚拟的圆环,取值范围为0~2^32-1。整个空间按顺时针组织,从0开始,直到2^32-1。
一致性哈希算法的使用:
- 先确定机器节点的位置:将机器的唯一身份作为key进行一致性哈希计算后,会得到一个数值,确定其在哈希环上的位置。
- 数据到了时,根据数据的key进行一致性哈希计算,也会得到一个数值,并能确定其在哈希环上的位置。然后,沿着“顺时针”的方向“查找”,第一台遇到的机器节点就是其定位的位置。
有什么缺点吗?
- 数据倾斜:当机器节点数太少时,会造成数据的分布不均,造成大部分数据都缓存在几个节点上。
解决方案:引入了虚拟节点,通过给每台机器新增一定数量的虚拟节点来实现。对数据key进行哈希计算定位到虚拟节点,然后通过虚拟节点找到其对应映射的实际机器节点,最后将数据存储在实际的机器节点上。这样能够避免因为服务节点少时数据倾斜问题。
一致性哈希算法的实现?用什么来作为哈希环?
应用场景?目前哪些框架支持?
Dubbo的ConsistentHashLoadBalance实现:
- 使用TreeMap存储虚拟节点,默认创建160个虚拟节点。
分布式锁
Redis常被用来做分布式锁,这里想讲下实际项目中分布式锁场景的应用。
分布式锁的实现有3种:
- 基于数据库乐观锁(唯一索引)、或悲观锁(for update)
- 基于Redis的set命令,set nx ex
- 基于Zookeeper的临时节点
实现和运维复杂度:数据库 < Redis < Zookeeper
性能方面:数据库 < Zookeeper < Redis
在实际工作中,针对不同类型、规模和要求的项目,会采取不同的策略:
单数据库/单Web实例/小业务量
这类项目一般是小型项目,客户无特殊要求,往往只有一台服务器,一个数据库,一个Web应用。对于业务可能存在的并发问题,直接在代码中加同步锁的方法实现。
单数据库/多Web实例/小业务量
这类项目因为存在多个Web实例,所以单应用的同步锁就无效了。为了降低技术复杂度以及运维成本(不在额外部署运维一个Redis),建议采用基于数据库实现分布式锁。
单数据库/多Web实例/大业务量
这类项目往往客户会对架构有要求,在技术方案设计中一般都有引入Redis,这时候就可以直接利用现有Redis来实现分布式锁。
方案的建议就是在现有技术框架内实现,而不是为了实现分布式锁额外引入新的工具,这样会得不偿失,会增加技术的复杂度和运维的工作量。