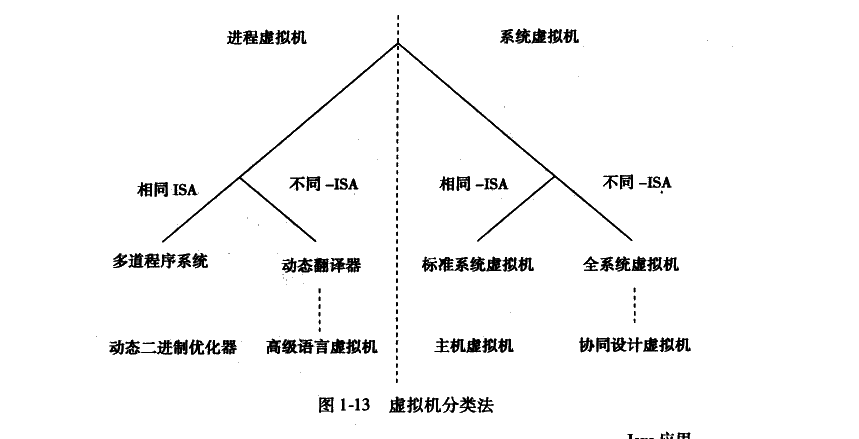
虚拟机分类
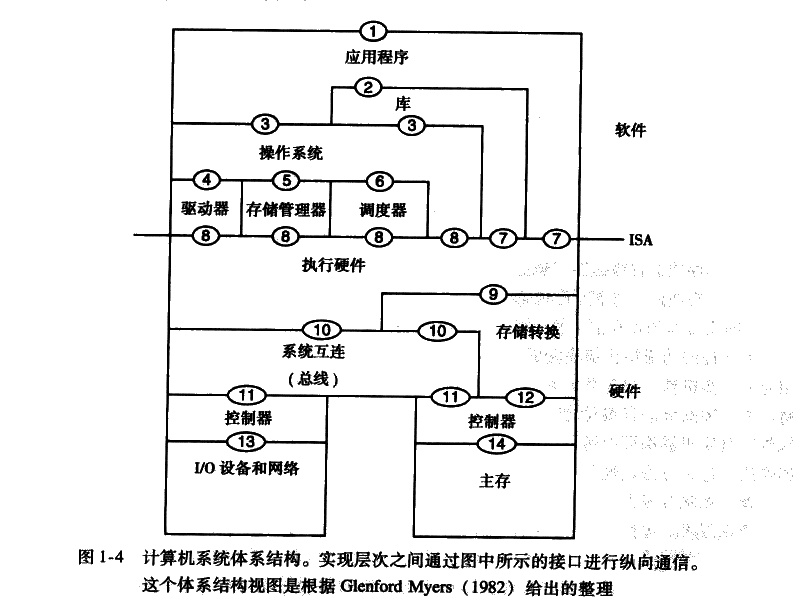
计算机体系结构
虚拟机分类
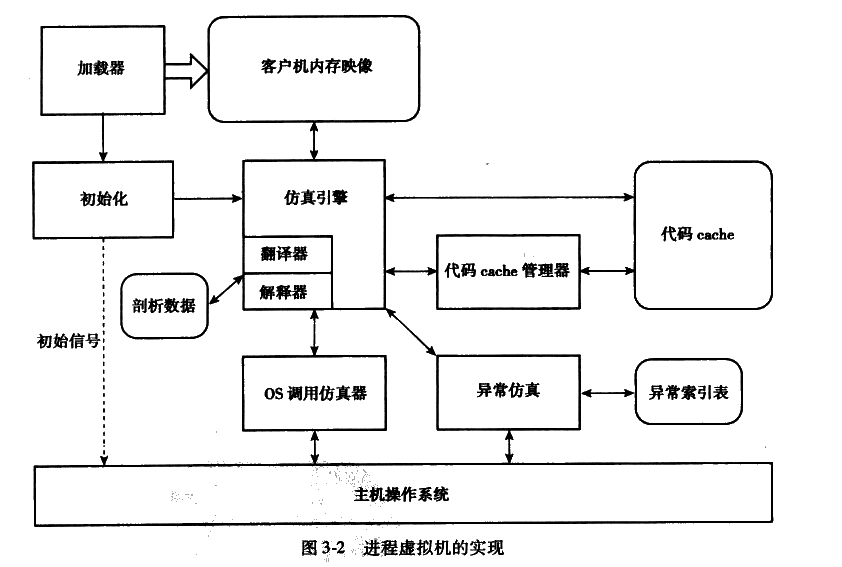
进程虚拟机
为用户应用程序提供虚拟的ABI环境。
进程虚拟机的实现
系统虚拟机
仿真技术
指令集仿真是许多虚拟机实现的一种重要支撑技术。由于仿真过程通常会损失一些性能,因此性能优化总是虚拟机实现的一个问题。高级语言虚拟机,二进制类采用了一个基于栈、字节码指令集。一个完整的ISA由许多部分组成,包括寄存器集合存储器结构、指令、陷阱和中断结构。指令集仿真技术的实现方式,其中一个是直接解释,另一个是二进制翻译。
解释
二进制翻译
高级语言虚拟机
Java指令集结构是基于栈的。
Java虚拟机的实现
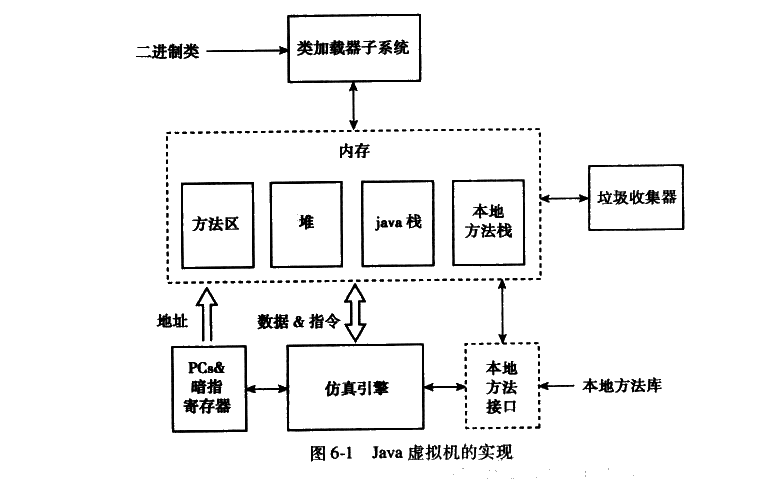
类加载器,一个Java虚拟机必须包含一个基本的类加载器,其操作被定义为JVM规范的一部分。另外,用户也可以定义类加载器作为类加载器子系统的一部分。在定位一个二进制类之后,加载器解析这个二进制类,并且将它翻译成可以被执行引擎仿真的内部数据结构。 垃圾收集器,实质上是每个JVM实现的一部分,尽管没有严格要求它作为JVM规范的一部分。 (1)标记清除收集器:标记,它从根引用开始跟踪所有可达对象,在达到每个对象时标记这个对象。清除,检查所有对象,凡是未被标记的对象被确定为垃圾。 (2)压缩收集器:将所有活动的对象移动到堆内存区域的顶部(或底部),剩下的就是一个连续的自由空间区域。 (3)复制收集器:
虚拟机介绍
计算机只能识别机器代码,例如0/1.用高级语言编写的代码,需要通过编译器,将源代码编译为机器代码。每个计算机的架构不同,指令集架构不同,对应的机器代码就不相同。这样导致每个源代码到了不同指令集架构的机器上,就要对应编译成该机器能识别的代码。
为了解决不同计算机架构带来的机器代码问题,虚拟机诞生了。虚拟机提供了一种叫做中间代码的格式。源代码通过编译器编译成虚拟机能识别的中间代码。然后由虚拟机来执行解释为机器代码。虚拟机屏蔽了不同计算机架构的底层实现,只要源代码都编译为虚拟机识别的中间代码。这样就可以通过虚拟机,使用同一套源代码同一套中间代码,能够运行在不同的计算机架构上了。
最著名的高级语言虚拟机就是Java虚拟机。不过这里要介绍下“规范”,然后“实现”都是基于特定“规范”的来实现的。Java虚拟机也有Java虚拟机规范,每个虚拟机实现都遵照相同的虚拟机规范,就能够兼容所有遵照Java虚拟机规范实现的中间代码。
虚拟机规范
现在我们先来看看虚拟机规范里是如何描述虚拟机的,虚拟机的结构,虚拟机需要实现的功能有哪些。虚拟机的工作原理是,首先加载中间代码,然后解析运行代码,最后退出。(本文参考的Java虚拟机规范为jvms8,Java语言规范为jls8)
- 中间代码 Java虚拟机里的中间代码是指字节码,即二进制表示的代码。虚拟机只执行符合规定的字节码,编译器也只是把源代码编译为符合规定的字节码。
- 加载器 虚拟机首先要能够加载代码,所以虚拟机需要有一个代码加载器,能够加载特定的中间代码,即字节码。
- 运行 代码加载完后就要开始执行代码,虚拟机将运行分为几个步骤:链接(验证,准备,解析)、初始化、执行
Java虚拟机主要分为五个概念:
- 虚拟机结构(Java Virtual Machine Architecture)
- 编译(Compiler)
- 字节码(Class File Format)
- 加载、链接与初始化(Loading、Linking and Initializing)
- 字节码指令(Instruction Set)
运行时区域
JVM将运行时区域分为
- 堆
垃圾收集的堆,用于存储对象和数组
- 方法区
运行时常量池,用于存储代码、常量、类的其它数据消息。“方法区”逻辑上也是属于“堆”的一部分,但虚拟机实现者可以将“方法区”从“堆”独立离出,例如,可以不对“方法区”进行垃圾回收。
- 栈
虚拟机的每个线程都要一个属于自己的“栈”空间,随着线程一起创建,用于存储栈帧。每当有一个方法被调用就会创建一个新的栈帧,方法退出时栈帧销毁。每个栈帧都提供了一个“操作数栈”和一个“本地变量表”数组。
栈分为虚拟机栈和本地方法栈,存储栈帧(本地变量表、操作数栈、动态链接(指向运行时常量池的引用))
- 寄存器(pc register) Java虚拟机允许多线程同时执行,每个线程都有属于自己的PC寄存器(程序计数器)。寄存器记录着当前正在执行的方法地址,如果这个方法是native本地方法,则为空。
堆和方法区是所有线程共享的区域。栈和寄存器为线程私有的区域。
字节码
Java虚拟机规范定义的中间代码为字节码,也叫做class文件。是一种以二进制表示的数据文件。编译器按照class文件格式规范将Java源代码编译成class文件,然后Java虚拟机执行class文件。现在先来看看虚拟机规范中是如何定义class文件格式的。
每个class文件都有一个ClassFile结构:
- Magic 表示这是一个class文件,固定值为0xCAFEBABE,用来标识这是一个class文件。虚拟机加载代码的时候会识别该字段.
- minor_version,major_version class文件格式的版本号
- constant_pool_count 常量池数量,Java代码里面定义的常量(字符串、字段名、方法名、类或接口名等)的数量。
- constant_pool[constant_pool_count - 1] 常量数组,存储常量。
- access_flags 类的访问权限标识,比如public、private等
- this_class 类索引,指向常量池的某一项,标识该类或接口名称
- super_class 父类索引,有父类则指向常量池的父类项;没有父类则为0
- inerfaces_count 实现的接口数量
- interfaces[inerfaces_count - 1] 具体接口名
- fields_count 字段数量
- fields[fields_count - 1] 具体字段名
- methods_count 方法数量
- method[methods_count - 1] 具体方法名
- attributes_count 属性数量
- attribute[attributes_count - 1] 具体属性名(get set)
加载器
Java虚拟机在加载字节码的时候,需要先验证字节码的格式是否正确,所以虚拟机规范里定义了字节码验证事项:
- 前四个字节必须是正确的魔数(magic number)。
- 能够辨识出来的所有属性都必须具备合适的长度。
- class文件的内容不能缺失,尾部也不能有多余字节。
- 常量池必须符合各项约束。
- 常量池中的所有字段引用及方法引用,都必须具备有效的名称、有效的类及有效的描述符。
即使一个虚拟机的实现都按照规范对字节码进行了格式检查,但是格式检查并不确保字段或某个方法真的在某个类中,也不确保某描述符会指向真实的类。格式检查只保证这些项的格式正确。更详细的检查,则是在运行阶段。
规范规定,字节码的加载是通过类加载器来加载的。虚拟机规范支持两种类加载器,一种是虚拟机自定义的引导类加载器,另一种是用户自定义类加载器,该类加载器必须是抽象类ClassLoader的某个子类的实例。类加载器通过直接定义或委托其他类加载器的方式来创建类。
当类被创建的时候,虚拟机会根据类结构中的常量池constant_pool来构建运行时常量池。运行时常量池中的所有引用最初都是符号引用。在链接阶段才会将符号引用转换为实际引用???。
加载器就是将class文件加载到内存中。
运行
执行代码前必须要先进行链接和初始化,链接包括验证、准备和解析。验证阶段就是前面所述的“格式检查”,准备阶段是创建类或接口的静态字段,并用默认值初始化这些字段。解析阶段将符号引用指向运行时常量池。
初始化就是执行类的初始化方法。Java虚拟机规范里规定只有发现下列行为时,类或接口才会被初始化:
- 在执行引用类或接口的:new、getstatic、putstatic或invokestatic虚拟机指令时。
- 在初次调用java.lang.invoke.MethodHandle实例时。
- 在调用类库中的某些反射方法时,例如,Class类或java.lang.reflect包中的反射方法。
- 在它被选定为Java虚拟机启动时的初始类时。 在类或接口初始化前,它必须被链接过,也就是经过验证、准备、解析阶段。
因为Java虚拟机是支持多线程的,所以在初始化类或接口的时候要特别注意线程同步问题。Java虚拟机实现需要负责处理好线程同步和递归初始化问题,具体可以使用下面的步骤来处理:
- Class对象已经被验证和准备过,但还没有被初始化。
- Class对象正在被其他特定线程初始化。
- Class对象已经成功被初始化且可以使用。
- Class对象处于错误的状态,可能因为尝试初始化时失败过。
每个类或接口C都有一个唯一的初始化锁LC。如何实现从C到LC的映射,可由Java虚拟机实现自行决定。例如,LC可以是C的Class对象,或者与Class对象相关的监视器。初始化C的过程如下:
- 同步C的初始化锁LC。
- 如果C的Class对象显示当前C的初始化是由其他线程正在进行的,那么当前线程就释放LC并进入阻塞状态,知道它知道初始化工作已经由其他线程完成,此时当前线程需要重试这一过程。
- 如果C的Class对象显示C的初始化正由当前线程进行,那就表明这是对初始化的递归请求。释放LC并正常返回。
- 如果C的Class对象显示Class已经初始化完成,那么就不需要再做什么了。释放LC并正常返回。
- 如果C的Class对象显示它处于一个错误的状态,那就不可能再完成初始化了。释放LC并抛出NoClassDefFoundError异常。
- 否则,记录下当前线程正在初始化C的Class对象,随后释放LC。根据属性出现在ClassFile的顺序,利用ConstantValue属性来初始化C中的每个final static字段。
- 接下来,如果C是类而不是接口,且它的父类SC还没有初始化,那就在SC上面也递归地进行完整的初始化过程。
- 之后,通过查询C的定义加载器来判定C是否开启了断言机制。
- 执行C的类或接口初始化方法。
- 如果正常执行了C的初始化方法,那就获取LC,并把C的Class对象标记成已经完全初始化,通知所有正在等待的线程,接着释放LC,正常地退出整个过程。
- 否则,C的初始化方法就必定因为抛出了一个异常E而中断退出。
- 获取LC,标记下C的Class对象有错误发生,通知所有正在等待的线程,释放LC,将E或上一步中的具体错误对象作为此次意外中断的原因。
Java虚拟机规范同时规定,Java虚拟机实现也可以省略1/4/5步的获取和释放LC锁,但是要先确认一些细节???(这里没看懂)
初始化完成后就开始执行代码,Java虚拟机规范定义了一套Java虚拟机指令集。编译器的功能就是讲Java源代码编译成Java虚拟机的指令集。Java虚拟机中的执行,就是将Java虚拟机指令集转换为特定CPU指令集,然后执行CPU指令。
虚拟机实现
上一章介绍了Java虚拟机规范定义的一些说明,现在来看看具体的Java虚拟机实现。看看这些“实现”是如何按照规范进行实现的。
Hotspot VM
对象
Hotspot VM使用C++实现,使用OOP-Klass二分模型将对象与类型分开表示。
OOP-Klass二分模型:
- OOP:ordinary object pointer 或 OOPS,即普通对象指针,用于描述对象的实例信息。
- Klass:Java类的C++对等体,用来描述Java类。
OOPS表示对象的实例数据,没有持有任何虚函数;Klass对象中含有VTBL虚函数表,能够根据Java对象的实际类型进行C++分发(dispatch)。这样一来,OOPS就可以通过Klass中的VTBL来找到所有的虚函数。这就避免了在每个对象中都分配一个C++ VTBL指针。
Klass向JVM提供两个功能:
- 实现语言层面的Java类;
- 实现Java对象的分发功能。
每创建一个Java对象,JVM就创建一个OOP对象来表示Java对象。OOPS类的共同基类型为oopDesc,有多种oopDesc子类,比如表示实例的instanceOopDesc和表示数组的arrayOopDesc。
在JVM内部通过instanceOopDesc结构来表示一个Java对象。对象在内存中的布局分为连续的两个部分:instanceOopDesc和实例数据。(这里要画一张,用图表来显示)
对象的创建 对象创建内存分配方式:指针碰撞和空闲列表。为每个线程分配一块TLAB空间。
对象分为对象头、实例数据和对其填充。对象头包括两部分信息,第一部分用于存储对象自身的运行时数据,另一部分是类型指针。实例数据存储对象的有效信息。对其填充仅起着占位符的作用。
对象的定位方式:使用句柄和直接指针两种。 句柄:堆中分配一块内存用作为句柄池,保存对象实例数据与类型数据的地址引用。 直接指针:堆中直接保存的是对象实例数据的地址,对象实例数据中保存类型数据的地址引用。
运行时数据结构
- 运行时数据区 堆和方法区的内存分配由HotSpot的内存管理模块维护,而内存的释放工作则由垃圾收集器自动完成。HotSpot中将虚拟机栈和本地方法栈合二为一。
HotSpot将方法区放在了永久代,垃圾收集器不会对其进行回收。不过在JDK9还是后续版本中好像移除了???
系统如何根据符号引用定位到实际存储对象的内存空间?常量池每一项都表示一个在Class文件中的索引号,通过索引来定位到方法或者字段的全限定名的。常量池项间允许互相引用。常量池解决了JVM定位字段和方法的问题,但是若每次都要解析常量池会带来性能下降,所以引入了常量池缓存(ConstantPoolCache)。
方法的解析:将符合引用转换成直接引用。通过以上方法可以获取到符号引用,在通过链接解析器(LinkResolver)对方法进行解析和查找。
解析过程(以类方法为例): 1)首先检查resolved_klass类型是否正确,排除接口类型。 2)在类以及它的超类中查找方法(方法表排序,使用二分查找)。如果未找到,则在类所实现的接口中查找,如果仍未找到,抛出NoSuchMethodError异常。 3)然后检查访问权限。
- GC
对象存活判定算法和垃圾收集算法
对象存活判定:引用计数和可达性分析
垃圾收集算法:复制算法、标记-清除算法、标记-整理算法、(基于图的?)
分代收集算法 将内存空间划分为新生代和老年代。新生代又被划分为1个Eden区和2个幸存区(Survivor),其中一个称为from区,另一个称为to区。新生代使用复制算法的垃圾回收策略,老年代使用基于标记-整理算法那的垃圾回收策略。新生代对象的生命周期短且频繁,适合使用复制算法。老年代对象的生命周期长,适合使用基于标记-整理算法的策略。
根据垃圾收集作用在不同的分代,垃圾收集类型分为两种: 1)Minor Collection:对新生代进行收集 2)Full Collection:除了对新生代收集,也对老年代进行收集。
新生代的垃圾收集算法:serial、parnew、parallel scavenge、g1收集器。老年代的垃圾收集算法:serial old、parallel old、cms、g1收集器。
JVM通过两个参数来判断对象是否可以晋升到老年代。 1)年龄:经历Minor GC的次数。默认7 -XX:InitialTenuringThreshold 2)大小:对象占用空间的大小。
内存分配策略
- 优先在新生代的Eden区分配,Eden区空间不足够时,虚拟机发起一次MinorGC。
- 大对象直接进入老年代,大对象是指需要大量连续内存空间的Java对象。
- 长期存活的对象将进入老年代,虚拟机为每个对象定义了一个对象年龄(Age)计数器。对象每经过一次Minor GC,Age加1,当Age增加到一定程度MaxTenuringThreshold将会被晋升到老年代中。
- 动态对象年龄判定,在Survivor区如果相同年龄对象大小总和大于Survivor区一半,则年龄大于该年龄的对象直接进入老年代。
- 空间分配担保,Minor GC,如果老年代最大连续空间小于新生代对象总空间,则检查最大连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,则尝试进行一次Minor GC。
快速分配
对于多线程应用,需要保证线程安全。HotSpot为每个线程都在堆中开辟了一个独立私有的TLABs区域,每个块TLABs使用碰撞指针技术(线性分配技术)进行内存分配。这样对于多线程场景下就不用使用锁来进行管理,实现了高效的分配策略。只有当一个TLAB填满时才需要进行同步再获取一个新的TLAB。
虚拟机开启UseTLAB选项,在分配一个对象时,会先尝试在TLAB中分配,如果分配失败,则再尝试使用加锁机制在Eden区分配。TLAB大小一般限制在Eden区的1%一下。
栈上分配(逃逸分析/逸出分析)
思路:局部变量作用域仅限于方法内,则直接在栈帧中分配对象空间,避免在堆中分配。这样做可以减少新生代的收集次数。HotSpot默认开启逸出分析。
- 垃圾收集器
串行收集器:Serial,采用单线程工作方式,在GC线程工作时,应用线程暂停工作(STW)。STW暂停时间的长短是这款收集器性能的指标,常见产品有: 1)Serial收集器,作用于新生代,基于“复制”算法。 2)Serial Old收集器,作用于老年代,基于“标记-整理”算法。
并行收集器:ParNew,采用多个GC线程并行收集。在GC线程工作时,应用线程也要暂停工作(STW)。多线程情况下极大的缩短STW时间。常见产品有: 1)ParNew收集器,作用于新生代,基于“复制”算法。 2)ParNew Old收集器,作用于老年代,基于“标记-整理”算法。
吞吐量优先收集器:Parallel Scanvenge。基于ParNew,可以设置预期收集时间,仅作用于新生代。
不同收集器对应的内存管理方式也有所区别,所以HotSpot还提供了一些VM选项,用来选择堆的类型。 1)比如启用了UseParallelGC,系统将自动选择堆类型为ParallelScavengeHeap。 2)若启用UseG1GC,系统自动选择堆类型为G1CollectedHeap,收集策略为G2专用的G1CollectorPolicy_BestRegionsFirst。 3)若都没配置,则默认堆类型GenCollectedHeap,收集策略为:
- 默认ConcurrentMarkSweepPolicy,老年代收集使用“标记-清除”算法;
-XX:+UseConcMarkSweepGC 使用并发收集器CMS,会自动开启 -XX:+UseParNewGC 即新生代使用多线程并行收集器ParNew -XX:+UseParallelGC 新生代使用多线程收集器Parallel Scavenge -XX:+UseParallelOldGC(自动开启 -XX:+UseParallelGC) 老年代使用Parallel收集器 -XX:PrintGCDetails 输出GC日志 -XX:UseSerialGC 新生代使用单线程的DefNew
根对象集合:
- 全局变量引用的对象
- 栈引用的对象
CMS收集器(并发标记-清除,Concurrent Mark-Sweep) CMS收集器,GC工作线程与应用线程可以并发执行。仅作用于老年代,使用-XX:+UseConcMarkSweepGC。“标记”阶段才需要STW。由于JVM系统运行的复杂性,不能做到随时暂停,所以引入了安全点(safepoint)概念。应用线程在执行过程中会轮询是否需要暂停标识,若需要则中断挂起。
CMS收集分为6个阶段:
- 初始标记,从根对象开始标记,只标记与根对象直接关联的对象,STW。
- 并发标记,与应用线程并发执行,从初始标记阶段标记的对象开始向下遍历所有对象。
- 并发预清理,与应用线程并发执行,重新扫描。
- 重新标记,STW,GC线程扫描在CMS堆中的对象。
- 并发清理,与应用线程并发执行,清理垃圾对象。
- 并发重置,重置CMS收集器的数据结构,做好下一次GC任务准备。
但是基于“标记-清除”算法的收集器会产生大量的内存碎片。
G1收集器(Gabage First) 重新定义堆空间,将堆划分为一个个区域。
- 解释器(interpreter)
对字节码解释执行。除了基本的解释器外,HotSpot将运行时频繁执行的代码编译成本地代码,执行编译任务的叫作即使编译器(JIT编译器 Just in Time Compiler)。
几种运行模式:
- 解释模式:-Xint
- 编译模式:-Xcomp
- 混合模式:-Xmixed
解释器由几个部分组成:
- 解释器(interpreter):HotSpot中有两种解释器,默认的模板解释器(TemplateInterpreter)和C++解释器(CppInterpreter)。
- 代码生成器(code generator):利用解释器的宏汇编器向代码缓存空间写入生成的代码。由Codelet来表示。
- InterpreterCodelet:由解释器运行的代码片段。
- 转发表(dispatch table):找到与字节码对应的机器码。模板解释器由两张转发表,正常模式表和进入safepoint表。
JIT编译器:
- 客户端编译器(Client Compiler,C1编译器),-client选项指定,对编译进行快速优化。
- 服务端编译器(Server Compiler,C2编译器),-server选项指定,对编译进行更多优化,编译比C1耗时,但代码高效。
Code Cache,代码高速缓存,生成和存储本地代码。包括已编译好的Java方法和RuntimeStubs等。Code Cache空间由虚拟机托管。
- 虚拟机监控工具
jdk自带命令工具
-
jps,可以查看虚拟机进程。-l 显示应用程序主类完整的包名或jar文件的完整路径;-m 显示传给主方法的参数;-v 显示传给jvm的启动参数。与linux的ps -ef grep java 命令相似。也可以查看远程服务器的jps信息,不过要开启jstatd服务。jps原理,就是java程序启动后,在linux的临时文件夹/tmp/hsperfdata_{username}/下生成以java进程的pid为名字的文件,里面包含了一些java程序的参数信息。通过解析该文件就可以获取到参数信息。 -
jinfo pid,查看JVM的完整参数,并可以动态调整部分参数。java -XX:+PrintFlagsFinal -version grep manageable 查看可动态修改的参数。jinfo -flag +[参数] pid,例如jinfo -flag +PrintGCDetails 2947,+启动参数-关闭参数 - jmap,jmap -dump:format=b,file=/usr/local/src/2947.hprof 2947,生成Heap Dump文件。
- jstack,线程分析工具。 jstack pid。
- jconsole,图形化实时显示应用程序运行状态,内存、线程、对象。应用程序需要配置参数和密码,然后客户端远程连接登录即可。
堆内存转储 1)Java Core,描述CPU信息的文件。主要保存Java应用各线程在某一时刻运行的位置,即JVM执行到哪一个类、哪一个方法、哪一行上。它是一个文本文件,打开后可以看到每一个线程的执行栈,以stack trace的方式呈现出来。通过对Java Core文件的分析可以得到应用是否卡在某一环节上,即在该环节运行的时间是否太长,例如数据库查询长期得不到响应。 2)Heap Dump,描述内存信息的文件。它是一个二进制文件,保存了某一时刻JVM堆中对象的内存使用情况,这种文件需要用相应的工具进行分析。Heap Dump最重要的作用之一就是用作分析系统中是否存在内存溢出的情况。 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/file.hprof
线程转储 步骤: 1)获取线程转储信息,使用jstack工具直接获得。 2)排除死锁 3)定位资源瓶颈 4)判断引起资源瓶颈的程序来源,对症下药
内存泄漏、内存溢出 都会导致应用程序出现问题,性能下降或挂起。 内存泄漏:是导致内存溢出的原因之一;内存泄漏积累起来将导致内存溢出。内存泄漏可以通过完善代码来避免;内存溢出可以通过调整配置参数来减少发生的频率,但无法彻底避免。
检测内存泄漏,定期对Java应用程序做一次heap dump。然后通过工具分析各对象实例,是否有异常对象。然后找到对应代码,分析原因。 检测内存溢出,
内存溢出常见: 1)OutOfMemoryError: Java heap space 堆溢出 内存溢出主要存在问题就是出现在这个情况中。当在JVM中如果98%的时间是用于GC且可用的 Heap size 不足2%的时候将抛出此异常信息。 2)OutOfMemoryError: PermGen space 非堆溢出(永久保存区域溢出) 这种错误常见在web服务器对JSP进行pre compile的时候。 如果你的WEB APP下都用了大量的第三方jar, 其大小超过了jvm默认的大小(4M)那么就会产生此错误信息了。 如果web app用了大量的第三方jar或者应用有太多的class文件而恰好MaxPermSize设置较小,超出了也会导致这块内存的占用过多造成溢出, 或者tomcat热部署时侯不会清理前面加载的环境,只会将context更改为新部署的,非堆存的内容就会越来越多。 3)OutOfMemoryError: unable to create new native thread. 无法创建新的线程
- 系统内存不足,无法为新线程分配内存,-Xss设置线程大小
- 创建线程数超过了操作系统的限制,ulimit -u 查看系统允许最大线程数
堆设置很大,垃圾收集时间增长,频率减少;堆设置过小,垃圾收集时间减少,频率增加。 -Xss线程栈大小。 -Xms初始Heap的大小。 -Xmx最大Heap的大小。
-XX:+PrintCommandLineFlags 查看JVM运行时参数的参数值和最初的默认值 -XX:+PrintFlagsFinal 显示可动态修改的参数,以及当前值 -XX:+PrintFlagsInitial 显示可动态修改的参数,以及默认值
| java -XX:+PrintFlagsInitial | grep UseCompressedOops |
| java -XX:+PrintFlagsFinal | grep UseCompressedOops |
JVM调优的时候会设置哪些参数呢?
逃逸分析 -XX:DoEscapeAnalysis JDK1.6后默认开启逃逸分析技术,借助逃逸分析技术JIT编译器可以实现以下优化技术: 1)对象展开 2)标量替换,将对象的字段直接分配到栈上,就不需要通过引用对象指针将字段载入,减少内存访问次数。 3)栈上分配,对于逃逸对象(不会被其他线程访问的对象)直接分配到栈上,减少对象在堆上分配的数目。 4)消除同步,对象上的锁不会被其他线程访问,编译器会移除无用的锁。 5)消除垃圾收集的读/写屏障,线程分配的对象不发生逃逸,
- 案例
1)OkHttpClient
“OkHttp ConnectionPool” #75 daemon prio=5 os_prio=0 tid=0x00007f6e1bf73000 nid=0x160f in Object.wait() [0x00007f6e50e5c000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:460)
at okhttp3.ConnectionPool$1.run(ConnectionPool.java:67)
- locked <0x00000000e4ce0f10> (a okhttp3.ConnectionPool) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) “
jstack查看到有非常多的OKHttp线程,OkHttpClient是使用共享连接池的,理应不会创建这么多线程才对。后来去看OKHttpClient源码文档,发现一个Client拥有一个连接池,官网推荐我们要共用Client,如果每个请求都创建一个Client,那每个Client就会创建一个connection pool。看到这个提醒后,立马去工程代码里面查看对应的OKHttpClient的业务代码,发现确实是每发送一个请求就创建了一个Client。
2) Linux工具配合使用
- top 查看系统所有运行进程的CPU和内存等运行情况
- top -p pid 查看指定进程
- top -Hp pid 查看进程的线程运行情况
- 找到异常线程,得到线程号对应的16进制 printf “%x\n” [线程号]
-
通过jstack打印出对应线程的运行情况 jstack pid grep -A 10 [线程号16进制] - 根据日志找到对应代码,分析代码
-
还可以查看代码中创建对象占用内存排行情况 jmap -histo pid grep -n [20]
3)tomcat 内存溢出
- -Xms和-Xmx设置相等,系统内存空间不足
- 多次热部署后,内存溢出
- Linux 小工具
1)清空日志小技巧 echo “” > [日志文件],将空字符写入覆盖已有日志文件。 2)free 查看系统内存使用情况 -m以M单位输出
注意:-Xms和-Xmx只是设置了JVM里的堆的大小,JVM运行时除了堆还有栈、永久代等内容。所以总的JVM内存是这些所有区域的综合。DirectBuffer占用的空间不包含在JVM中,所以除了JVM还要监控DirectBuffer占用的空间大小。
-Xms和-Xmx设置相等 空余内存小于40%,JVM会调整内存直到最大-Xmx限制;空余内存大于70%,JVM会减少内存直到-Xms最小限制。所以一般会设置-Xms和-Xmx相等,防止每次GC后JVM调整堆大小,减少开销。
GC不会对永久代进行回收,所以如果应用程序有很多类信息的话,也可能出现永久代内存溢出。
tomcat热部署功能在调试阶段可以使用,生产阶段最好禁止reloadable设为false。tomcat热部署后,会清空原来的引用,创建一个新的ClassLoader,重新加载类,不会清空永久代。所以永久代会越来越大。热加载,不清空session、不释放内存。
类加载
类整个生命周期:加载、链接(验证、准备、解析)、初始化、使用、卸载。其实解析阶段也可以在初始化后进行。 初始化时机: 1)遇到new、getstatic、putstatic、invokestatic这4条字节码指令。 2)使用java.lang.reflect包的方法对类进行反射调用。 3)初始化类时,发现父类未初始化,触发父类的初始化。 4)虚拟机启动时指定的主类。 5)JDK1.7之后的动态语言特性,java.lang.invoke.MethodHandle实例最后的解析结果的方法句柄。java -XX:+PrintFlagsFinal -version|grep manageable 输出可修改的参数列表。
类加载器
解释器
HotSpot中实现了两种具体的解释器,即模板解释器(TemplateInterpreter子模块,没有使用“编译优化”,只是纯粹的解释执行,HotSpot默认解释器)和C++解释器(CppInterpreter子模块)。
JVM的启动
JVM的进程入口是在…\jdk\src\share\bin\main.c
- 创建jvm装载环境和配置
- 装载jvm.dll
- 初始化jvm.dll并挂界到JNIENV(JNI调用接口)实例
- 调用JNIEnv实例装载并处理class类。
Prims模块 对外提供访问接口,包括四个子模块
- JNI模块 Java本地接口模块,允许Java程序与本地代码进行交互。
- JVM模块 虚拟机对外提供的一些函数,以“JVM_”为前缀名。
- JVMTI模块 提供一种编程接口,允许程序员创建代理监视和控制Java应用程序。
- Perf模块 JDK中sun.misc.Perf类的底层实现,由外部程序调用,以监视虚拟机内部的Perf Data计数器。
Services模块为JVM提供了JMX等功能,支持对Java应用程序进行管理和监控。
Runtime模块 运行时模块,为其他系统组件提供运行时支持。
JRockit VM
Maxine VM
Graal VM
Kilobyte VM
KVM使用instanceStruct结构来表示class运行时的实例,instanceClassStruct结构指向class文件。创建一个class类的实例instance时,这个instance以instanceStruct结构来表示,instance与class之间的关系,通过instanceStruct结构的ofClass字段表示。ofClass字段指向instanceClassStruct结构。
同一个class创建多个instances,它们各自拥有互相独立的instance fields内存值。每个实例的instanceStruct结构里都有data[]数组属性用来保存各自的instance variable值。data[]数组即保存本class中的instance variables值还保存super class中的instance variables值。
KVM将类的加载过程分为4个阶段:
- CLASS_RAW 0 为class配置一块instanceClassStruct结构,填好class的声明部分
- CLASS_LOADING 1 从Java类中载入class的定义部分
- CLASS_LOADED 2 载入实例化interfaces的内容及子集instance variable的信息
- CLASS_LINKED 3 完成额外信息的定义
KVM在运行Java程序的同时会定义许多的runtime data areas。
- Java heap 分成两个部分:permanent space 以及 heap space。class结构分配在permanent space中,instance结构分配在heap space中。heap space会被garbage collector自动回收,permanent space不会。Java heap是以cell为单位,cell表示4个bytes,所以heap的容量是4的倍数。
- Java execution stack 创建thread的同时,会在heap中分配一个专属该thread的execution stack,stack中保存的数据结构是frame。stack是以链接串行的概念来动态扩大或缩小其容量。
Lua虚拟机学习
Lua从5.0开始从基于栈的虚拟机(stack-based vm)改为基于寄存器的虚拟机(register-based vm)。
Lua虚拟机垃圾收回是采用标记清除算法策略对内存进行回收。GC主要回收的是string table function thread 四种引用类型和proto和upvalue。如果是需要被GC管理的对象,就以GCObject指针形式保存。所有GCObject都有一个相同的数据头,叫作CommonHeader。所有GCObject都用一个单向链表串起来。但是string类型除外,string是放在hash表中,单独管理,所以不再链表中。除string外的GCObject链表头在rootgc域中。该域在初始化时被初始化为主线程。每当一个新的GCObject被创建出来,都会被挂接到这个链表上。
mainthread为链表尾节点,userdata类型被创建时,将被挂接在mainthread后面。
Lua中的标记清除只要遍历整个GCObject链表,把未被标记的节点删除即可。?那标记阶段是遍历另外的根集合还是这个GCObject链表?
lua_State用于表示lua vm的某种状态,其也是一个类型为thread的GCObject。一个完整的lua虚拟机在运行时,可有多个lua_State,它们会共享一些数据,比如GCObject链表。这些数据都放在global_State *1_G域中。string类型则以stringtable结构(hash表)保存在stringtable strt域中。string的值类型为TString,它和其他GCObject一样,拥有CommandHear,但其中的next域不是链表作用,是被挂接到stringtable中的。
Lua的GC分为5个过程 GCSpause 0 GCSpropagate 1 GCSsweepstring 2 GCSsweep 3 GCSfinalize 4,5个状态存放在global state的gcstate域中。
GCSpause标记系统的根节点,执行markroot函数、GCSpropagate迭代标记子几点、GCSsweepstring标记string类型数据、GCSsweep清理所有未标记的的GCObject、GCSfinalize调用gc元方法的userdata对象。
每个对象创建时会被标记为白色,颜色保存在GCObject的CommonHeader的marked域中,以位形式存放。在标记阶段,可达的节点逐个被标记为黑色。
收集器相关的api有luaC_step和luaC_fullgc,还有一个luaC_checkGC。在大部分会导致内存增长的api中,都会调用luaC_checkGC,保证gc可以随内存使用的增加而进行。使用自动gc会有个问题就是,它很可能使系统的峰值内存占用远超过实际需求了。因为收集行为常常在调用栈很深的地方,往往会引用众多临时对象,这个时候做mark工作,会导致这些对象都被mark住。可以调用LUA_GCSTOP停止自动GC。
luaC_fullgc用于执行一次完整gc。GC的核心在于singlestep函数,luaC_step调用singlestep的次数与gcstepmul值。自动GC,当totalbytes大于等于GCthreshold时,就会触发luaC_step。每次luaC_step,GCthreshold都会被调高1K直到GCthreshold追上totalbytes。
singlestep的返回值决定GC的进度,在GCSpropagate阶段,每mark一个灰色节点,就返回了它实际占用的内存字节数作为quantity值。
GCSsweep清理两种对象,一种string,另一种GCObject。在GCSsweepstring中,每步调用sweepwholelist清理strt这个hash表中的一列。在该阶段,string有可能清理不干净。因为string是存储在table里的,当table进行rehash时,被标记的string有可能被重新分配到已清理的列里。在GCSsweep中,清理是整个GCObject链表,分段完成。sweepgc指针用于记录遍历位置,每次遍历GCSWEEPMAX个元素。